Come stiamo rendendo l’infrastruttura di Roblox più efficiente e resiliente
by Daniel Sturman, Chief Technology Officer; Max Ross, Vice President, Engineering; and Michael Wolf, Technical Director
Prodotto & Tecnologia
Man mano che Roblox è cresciuto negli ultimi 16+ anni, sono aumentate anche la portata e la complessità dell’infrastruttura tecnica che supporta milioni di co-esperienze 3D immersive. Il numero di macchine che supportiamo è più che triplicato negli ultimi due anni, da circa 36.000 al 30 giugno 2021 a quasi 145.000 oggi. Supportare queste esperienze sempre attive per persone in tutto il mondo richiede più di 1.000 servizi interni. Per aiutarci a controllare i costi e la latenza di rete, distribuiamo e gestiamo queste macchine come parte di un’infrastruttura cloud privata ibrida e personalizzata che viene eseguita principalmente in sede.
La nostra infrastruttura supporta attualmente più di 70 milioni di utenti attivi ogni giorno in tutto il mondo, inclusi i creatori che fanno affidamento sull’economia di Roblox per le loro imprese. Tutti questi milioni di persone si aspettano un livello di affidabilità molto elevato. Data la natura immersiva delle nostre esperienze, c’è una tolleranza estremamente bassa per ritardi o latenza, per non parlare di interruzioni. Roblox è una piattaforma per la comunicazione e la connessione, dove le persone si incontrano in esperienze 3D coinvolgenti. Quando le persone comunicano come avatar in uno spazio immersivo, anche piccoli ritardi o anomalie sono più evidenti rispetto a un thread di testo o una teleconferenza.
INell’ottobre 2021 si è verificata un’interruzione a livello di sistema. Tutto è iniziato in piccolo, con un problema in un componente in un data center. Ma si è diffuso rapidamente mentre stavamo indagando e alla fine ha provocato un’interruzione di 73 ore. All’epoca condividevamo entrambi dettagli su quanto accaduto e alcuni dei nostri primi insegnamenti dall’ accaduto. Da allora, abbiamo studiato questi insegnamenti e lavorato per aumentare la resilienza della nostra infrastruttura ai tipi di guasti che si verificano in tutti i sistemi su larga scala a causa di fattori quali picchi estremi di traffico, condizioni meteorologiche, guasti hardware, bug software o semplicemente gli esseri umani commettono errori. Quando si verificano questi guasti, come possiamo garantire che un problema in un singolo componente o gruppo di componenti non si diffonda all’intero sistema? Questa domanda è stata al centro della nostra attenzione negli ultimi due anni e, mentre il lavoro è in corso, ciò che abbiamo fatto finora sta già dando i suoi frutti. Ad esempio, nella prima metà del 2023, abbiamo risparmiato 125 milioni di ore di coinvolgimento al mese rispetto alla prima metà del 2022. Oggi condividiamo il lavoro che abbiamo già svolto, nonché la nostra visione a lungo termine per la costruzione di un sistema infrastrutturale più resiliente.
Costruire un Backstop
All’interno dei sistemi infrastrutturali su larga scala, i guasti su piccola scala si verificano molte volte al giorno. Se una macchina ha un problema e deve essere messa fuori servizio, è gestibile perché la maggior parte delle aziende mantiene più istanze dei propri servizi back-end. Pertanto, quando una singola istanza fallisce, altre si fanno carico del carico di lavoro. Per risolvere questi frequenti errori, le richieste sono generalmente impostate per riprovare automaticamente se ricevono un errore.
Ciò diventa difficile quando un sistema o una persona riprova in modo troppo aggressivo, il che può diventare un modo per propagare questi errori su piccola scala attraverso l’infrastruttura ad altri servizi e sistemi. Se la rete o un utente riprova con sufficiente insistenza, finirà per sovraccaricare ogni istanza di quel servizio e potenzialmente altri sistemi a livello globale. La nostra interruzione del 2021 è stata il risultato di qualcosa che è abbastanza comune nei sistemi su larga scala: un guasto inizia in piccolo e poi si propaga attraverso il sistema, diventando così grande così rapidamente che è difficile risolverlo prima che tutto si interrompa.
Al momento dell’interruzione, avevamo un data center attivo (con componenti al suo interno che fungevano da backup). Avevamo bisogno della possibilità di eseguire il failover manuale su un nuovo data center quando un problema bloccava quello esistente. La nostra prima priorità era assicurarci di avere una distribuzione di backup di Roblox, quindi abbiamo creato quel backup in un nuovo data center, situato in una regione geografica diversa. Ciò ha aggiunto protezione per lo scenario peggiore: un’interruzione che si estende a un numero sufficiente di componenti all’interno di un data center da renderlo completamente inutilizzabile. Ora disponiamo di un data center che gestisce i carichi di lavoro (attivo) e uno in standby che funge da backup (passivo). Il nostro obiettivo a lungo termine è passare da questa configurazione attivo-passivo a una configurazione attivo-attivo, in cui entrambi i data center gestiscono i carichi di lavoro, con un bilanciatore del carico che distribuisce le richieste tra loro in base a latenza, capacità e integrità. Una volta implementato questo, prevediamo di avere un’affidabilità ancora maggiore per tutto Roblox e di essere in grado di eseguire il failover quasi istantaneamente anziché nell’arco di diverse ore.
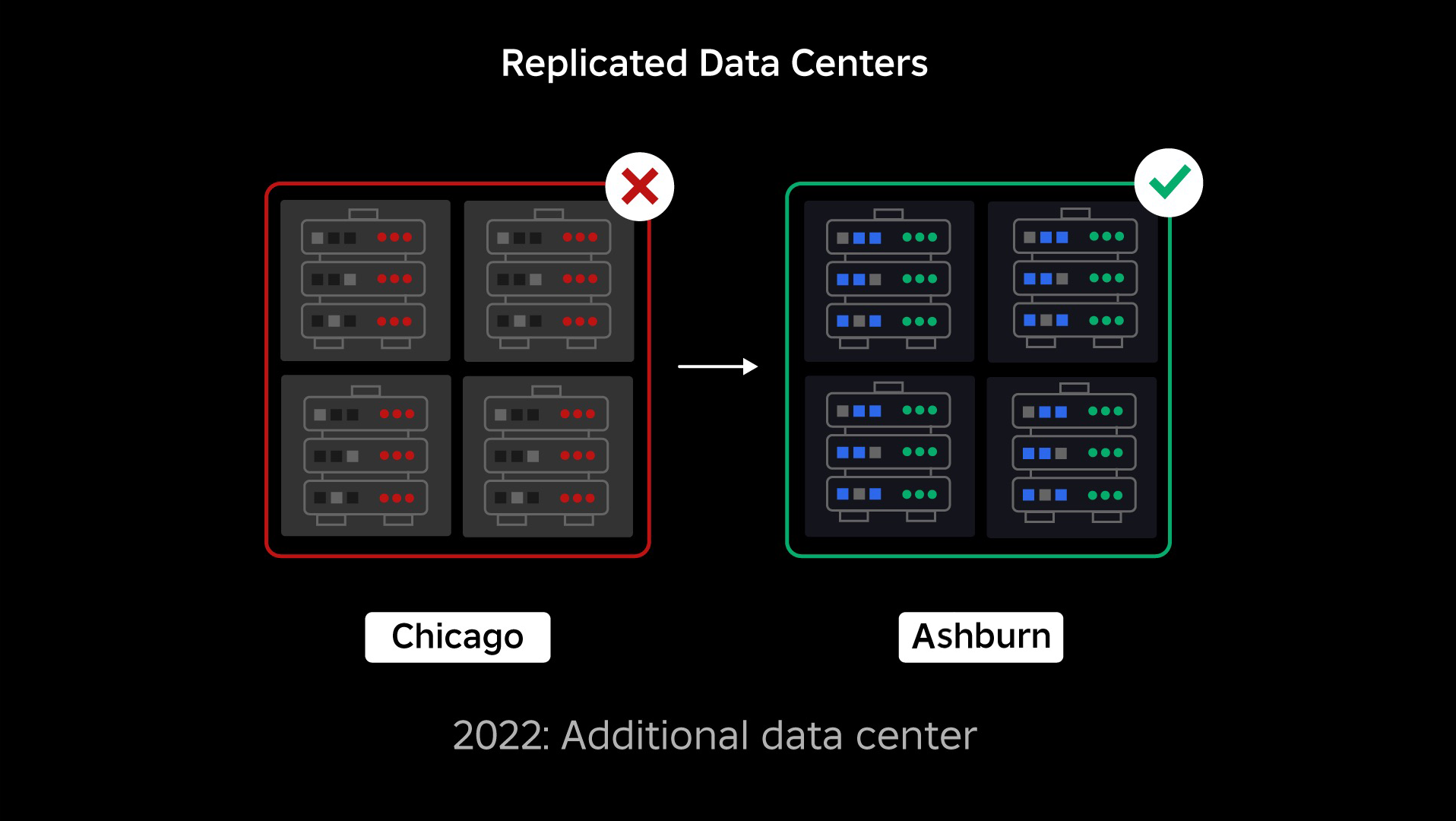
Passaggio a un’infrastruttura cellulare
La nostra priorità successiva era creare robusti muri anti-esplosione all’interno di ogni data center per ridurre la possibilità che un intero data center fallisse. Le cellule (alcune aziende le chiamano cluster) sono essenzialmente un insieme di macchine e sono il modo in cui creiamo questi muri. Replichiamo i servizi sia all’interno che tra le celle per una maggiore ridondanza. In definitiva, vogliamo che tutti i servizi di Roblox funzionino in celle in modo che possano beneficiare sia di forti muri anti-esplosione che di barriere anti-esplosione ISe una cella non è più funzionante può essere tranquillamente disattivata. La replica tra celle consente al servizio di continuare a funzionare mentre la cella viene riparata. In alcuni casi, la riparazione cellulare potrebbe significare un completo riapprovvigionamento della cellula. In tutto il settore, la cancellazione e il reprovisioning di una singola macchina, o di un piccolo insieme di macchine, è abbastanza comune, ma farlo per un’intera cella, che contiene circa 1.400 macchine, non lo è.
For this tAffinché ciò funzioni, queste celle devono essere ampiamente uniformi, in modo da poter spostare i carichi di lavoro da una cella all’altra in modo rapido ed efficiente. Abbiamo stabilito determinati requisiti che i servizi devono soddisfare prima di essere eseguiti in una cella. Ad esempio, i servizi devono essere containerizzati, il che li rende molto più portabili e impedisce a chiunque di apportare modifiche alla configurazione a livello del sistema operativo. Abbiamo adottato una filosofia di infrastruttura come codice per le celle: nel nostro repository di codice sorgente includiamo la definizione di tutto ciò che è presente in una cella in modo da poterla ricostruire rapidamente da zero utilizzando strumenti automatizzati.
Non tutti i servizi attualmente soddisfano questi requisiti, quindi abbiamo lavorato per aiutare i proprietari dei servizi a soddisfarli ove possibile e abbiamo creato nuovi strumenti per semplificare la migrazione dei servizi nelle celle quando pronti. Ad esempio, il nostro nuovo strumento di distribuzione “stripa” automaticamente la distribuzione del servizio tra le celle, in modo che i proprietari del servizio non debbano pensare alla strategia di replica. Questo livello di rigore rende il processo di migrazione molto più impegnativo e dispendioso in termini di tempo, ma il risultato a lungo termine sarà un sistema in cui:
- È molto più semplice contenere un guasto e impedire che si diffonda ad altre cellule;
- I nostri ingegneri delle infrastrutture possono essere più efficienti e muoversi più rapidamente;
- E Gli ingegneri che creano i servizi a livello di prodotto che vengono infine distribuiti nelle celle non hanno bisogno di sapere o preoccuparsi di quali celle vengono eseguiti i loro servizi.
Risolvere sfide più grandi
In modo simile al modo in cui le porte tagliafuoco vengono utilizzate per contenere le fiamme, le celle agiscono come forti muri anti-esplosione all’interno della nostra infrastruttura per aiutare a contenere qualsiasi problema stia provocando un guasto all’interno di una singola cella. Alla fine, tutti i servizi che compongono Roblox verranno distribuiti in modo ridondante all’interno e tra le celle. Una volta completato questo lavoro, i problemi potrebbero ancora propagarsi abbastanza da rendere inutilizzabile un’intera cella, ma sarebbe estremamente difficile che un problema si propaghi oltre quella cella. E se riusciamo a rendere le celle intercambiabili, il ripristino sarà significativamente più veloce perché saremo in grado di eseguire il failover su una cella diversa ed evitare che il problema si ripercuota sugli utenti finali.
Il punto in cui ciò diventa complicato è separare queste celle abbastanza da ridurre la possibilità di propagare errori, mantenendo le cose performanti e funzionali. In un sistema infrastrutturale complesso, i servizi devono comunicare tra loro per condividere query, informazioni, carichi di lavoro, ecc. Mentre replichiamo questi servizi nelle cellule, dobbiamo riflettere su come gestire la comunicazione incrociata. In un mondo ideale, reindirizziamo il traffico da una cellula malata ad altre cellule sane. Ma come gestiamo una “query of death”? causando una cellula per essere malsana? causando una cellula di diventare malsana? Se reindirizziamo la query a un’altra cella, la cella potrebbe diventare malsana proprio come stiamo cercando di evitare. Dobbiamo trovare meccanismi per spostare il traffico “buono” dalle cellule malsane, rilevando e reprimendo al tempo stesso il traffico che rende le cellule malsane.
Nel breve termine, abbiamo distribuito copie dei servizi informatici su ciascuna cella di calcolo in modo che la maggior parte delle richieste al data center possano essere soddisfatte da una singola cella. Stiamo anche bilanciando il carico del traffico tra le celle. Guardando più lontano, abbiamo iniziato a costruire un processo di scoperta dei servizi di prossima generazione che sarà sfruttato da un service mesh, che speriamo di completare nel 2024. Ciò ci consentirà di implementare policy sofisticate che consentiranno la comunicazione tra celle solo quando non avrà un impatto negativo sulle celle di failover. Nel 2024 arriverà anche un metodo per indirizzare le richieste dipendenti a una versione del servizio nella stessa cella, che ridurrà al minimo il traffico tra celle e quindi ridurrà il rischio di propagazione dei guasti tra celle.
Al picco, oltre il 70% del traffico dei nostri servizi back-end viene servito fuori dalle celle e abbiamo imparato molto su come creare celle, ma prevediamo ulteriori ricerche e test mentre continuiamo a migrare i nostri servizi fino al 2024 e al di là. Man mano che avanziamo, questi muri anti-esplosione diventeranno sempre più forti.
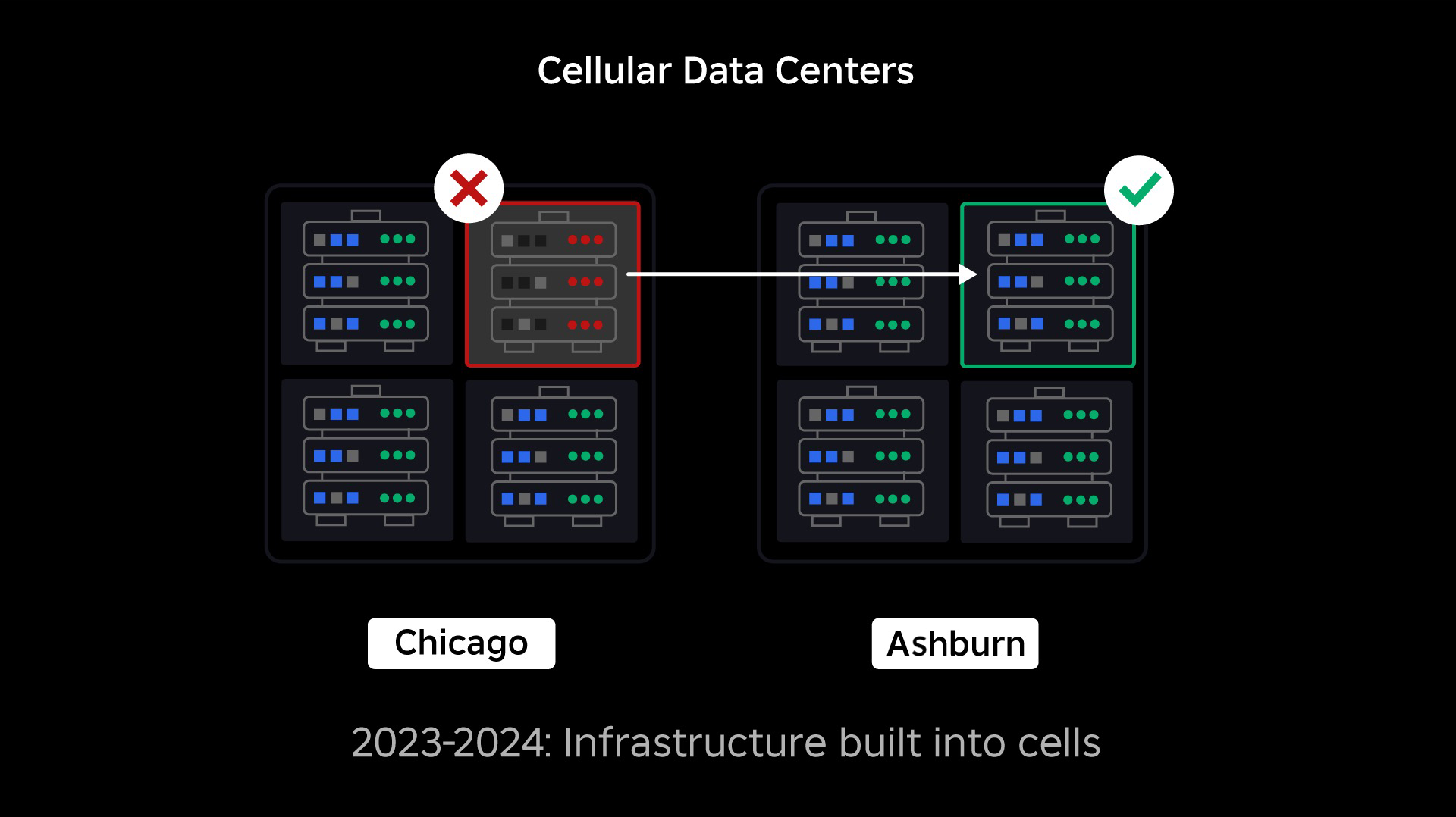
Migrazione di un’infrastruttura sempre attiva
Roblox è una piattaforma globale che supporta utenti in tutto il mondo, quindi non possiamo spostare i servizi durante gli orari non di punta o di inattività, il che complica ulteriormente il processo di migrazione di tutte le nostre macchine nelle celle e l’esecuzione dei nostri servizi in tali celle. Disponiamo di milioni di esperienze sempre attive che devono continuare a essere supportate, anche quando spostiamo le macchine su cui vengono eseguite e i servizi che le supportano. Quando abbiamo avviato questo processo, non avevamo decine di migliaia di macchine inutilizzate e disponibili su cui migrare questi carichi di lavoro.
Avevamo, tuttavia, un piccolo numero di macchine aggiuntive che sono state acquistate in previsione della crescita futura. Per iniziare, abbiamo costruito nuove celle utilizzando quelle macchine, quindi abbiamo migrato i carichi di lavoro su di esse. Apprezziamo l’efficienza e l’affidabilità, quindi invece di acquistare più macchine una volta esaurite le macchine “di riserva”, abbiamo costruito più celle cancellando e riapprovvigionando le macchine da cui eravamo migrati. Abbiamo quindi migrato i carichi di lavoro su quelle macchine sottoposte a nuovo provisioning e abbiamo riavviato il processo da capo. Questo processo è complesso: man mano che le macchine vengono sostituite e rese disponibili per essere integrate nelle cellule, non si liberano in modo ideale e ordinato. Sono fisicamente frammentati nei data hall, costringendoci a fornirli in modo frammentario, il che richiede un processo di deframmentazione a livello hardware per mantenere le posizioni hardware allineate con domini di guasti fisici su larga scala.
Una parte del nostro team di ingegneri dell’infrastruttura si concentra sulla migrazione dei carichi di lavoro esistenti dal nostro ambiente legacy, o “pre-cella”, alle celle. Questo lavoro continuerà finché non avremo migrato migliaia di diversi servizi infrastrutturali e migliaia di servizi back-end in celle di nuova costruzione. Prevediamo che ciò richiederà tutto il prossimo anno e forse fino al 2025, a causa di alcuni fattori complicanti. Innanzitutto, questo lavoro richiede la costruzione di strumenti robusti. Ad esempio, abbiamo bisogno di strumenti per ribilanciare automaticamente un gran numero di servizi quando implementiamo una nuova cella, senza alcun impatto sui nostri utenti. Abbiamo anche visto servizi creati partendo da presupposti sulla nostra infrastruttura. Dobbiamo rivedere questi servizi in modo che non dipendano da cose che potrebbero cambiare in futuro man mano che ci spostiamo nelle cellule. Abbiamo anche implementato un modo per cercare modelli di progettazione noti che non funzioneranno bene con l’architettura cellulare nonché un processo di test metodico per ciascun servizio migrato. Questi processi ci aiutano a evitare qualsiasi problema rivolto agli utenti causato dall’incompatibilità di un servizio con le celle.
Oggi quasi 30.000 macchine vengono gestite da cellule. ISi tratta solo di una frazione della nostra flotta totale, ma finora la transizione è stata molto fluida, senza alcun impatto negativo sui giocatori. Il nostro obiettivo finale è che i nostri sistemi raggiungano il 99,99% di uptime degli utenti ogni mese, il che significa che non interromperemo più dello 0,01% delle ore di coinvolgimento. A livello di settore, i tempi di inattività non possono essere completamente eliminati, ma il nostro obiettivo è ridurre qualsiasi tempo di inattività di Roblox a un livello quasi impercettibile.
A prova di futuro mentre cresciamo
Anche se i nostri primi sforzi si stanno rivelando efficaci, il nostro lavoro sulle cellule è lungi dall’essere terminato. Man mano che Roblox continua a crescere, continueremo a lavorare per migliorare l’efficienza e la resilienza dei nostri sistemi attraverso questa e altre tecnologie. Man mano che procediamo, la piattaforma diventerà sempre più resiliente ai problemi e qualsiasi problema che si verifichi dovrebbe diventare progressivamente meno visibile e distruttivo per le persone sulla nostra piattaforma.
In sintesi, ad oggi, abbiamo:
- Costruito un secondo data center e raggiunto con successo lo stato attivo/passivo.
- Abbiamo creato celle nei nostri data center attivi e passivi e migrato con successo oltre il 70% del traffico dei nostri servizi back-end in queste celle.
- Stabiliti i requisiti e le migliori pratiche che dovremo seguire per mantenere uniformi tutte le celle mentre continuiamo a migrare il resto della nostra infrastruttura.
- Dato il via a un processo continuo di costruzione di “muri anti-esplosione” più forti tra le cellule.
Man mano che queste celle diventano più intercambiabili, ci sarà meno diafonia tra le celle. Ciò sblocca alcune opportunità molto interessanti per noi in termini di aumento dell’automazione nel monitoraggio, nella risoluzione dei problemi e persino nello spostamento automatico dei carichi di lavoro.
A settembre abbiamo anche iniziato a eseguire esperimenti attivo/attivo nei nostri data center. Questo è un altro meccanismo che stiamo testando per migliorare l’affidabilità e ridurre al minimo i tempi di failover. Questi esperimenti hanno contribuito a identificare una serie di modelli di progettazione del sistema, in gran parte relativi all’accesso ai dati, che dobbiamo rielaborare mentre ci sforziamo di diventare pienamente attivi-attivi. Nel complesso, l’esperimento ha avuto un successo tale da lasciarlo in esecuzione per il traffico proveniente da un numero limitato di nostri utenti.
Siamo entusiasti di continuare a portare avanti questo lavoro per portare maggiore efficienza e resilienza alla piattaforma. Questo lavoro sulle celle e sulle infrastrutture attivo-attivo, insieme agli altri nostri sforzi, ci consentirà di diventare un servizio affidabile e ad alte prestazioni per milioni di persone e di continuare a crescere mentre lavoriamo per connettere un miliardo di persone in tempo reale.