Como estamos tornando a infraestrutura da Roblox mais eficiente e resiliente
by Daniel Sturman, Chief Technology Officer; Max Ross, Vice President, Engineering; and Michael Wolf, Technical Director
Tecnologia
Durante o crescimento da Roblox nos últimos 16 anos, a escala e complexidade da infraestrutura técnica que suporta milhões de co-experiências 3D também cresceu bastante. O número de máquinas que suportamos mais do que triplicou nos dois últimos anos, de cerca de 36 mil em 30 de junho de 2021 para 145 mil hoje. Suportar essas experiências sempre ligadas para todas as pessoas do mundo requer mais de 1000 serviços internos. Para nos ajudar a controlar custos e latência de rede, nós distribuímos e gerenciamos essas máquinas como parte de uma infraestrutura de nuvem privada e personalizada, que é executada primariamente no local.
Nossa atual infraestrutura suporta mais de 70 milhões de usuários ativos diários do mundo todo, incluindo os criadores que dependem da economia da Roblox para seus negócios. Essas milhões de pessoas esperam um alto nível de confiabilidade. Dada a natureza imersiva de nossas experiências, há uma tolerância baixíssima para latência ou atrasos, muito menos para quedas. A Roblox é uma plataforma para comunicação e conexão, onde as pessoas se reúnem em experiências 3D imersivas. Quando as pessoas estão se comunicando como seus avatares em um espaço imersivo, até os menores atrasos ou problemas são mais notáveis do que quando elas estão em uma conversa por texto ou uma chamada em conferência.
Em outubro de 2021, nós passamos por uma queda geral de sistema. Ela começou pequena, com um problema em um componente de uma central de dados. Logo ela se espalhou rapidamente enquanto estavamos investigando e finalmente isso resultou em uma queda de 73 horas. Na época, compartilhamos os detalhes sobre o ocorrido e algumas das lições que aprendemos com o problema. Desde então, estivemos estudando essas lições e trabalhando para aumentar a resiliência de nossa infraestrutura contra os tipos de falhas que ocorrem em todos os sistemas de larga escala devido a fatores, como picos extremos de tráfego, clima, erros de hardware, bugs de software ou simplesmente humanos cometendo erros. Quando essas falhas ocorrem, como podemos garantir que um problema com um único componente ou grupo de componentes não se espalhe para todo o sistema. Essa questão tem sido nosso foco nos últimos dois anos e enquanto o trabalho é contínuo, o que estivemos fazendo já tem valido a pena. Por exemplo, na primeira metade de 2023, salvamos 125 milhões de horas de engajamento por mês comparado com a primeira metade de 2023. Hoje, compartilhamos o trabalho já feito, bem como nossa visão a longo prazo para construir uma infraestrutura de sistema mais resiliente.
Construindo um “Freio traseiro”
Em infraestruturas de sistema de larga escala, pequenos erros de escala ocorrem várias vezes ao dia. Se uma máquina tem um problema e precisa ser removida do serviço, isso é gerenciável, pois a maioria das empresas mantém múltiplas instâncias de seus serviços de back-end. Então, quando uma única instância falha, outras a substituem. Para corrigir essas falhas frequentes, solicitações são geralmente configuradas para automaticamente tentar novamente se elas receberem um erro.
Isso se torna desafiador quando um sistema ou pessoa retenta muito agressivamente, o que pode se tornar uma maneira de essas falhas em pequena escala se propagarem através da infraestrutura para outros serviços e sistemas. Se a rede ou um usuário retenta persistentemente o suficiente, isso vai acabar sobrecarregando todas as instâncias daquele serviço e potencialmetne outros sistemas globalmente. Nossa queda de 2021 foi o resultado de algo que é muito comum em sistemas de larga escala: uma falha que começa pequena e se propaga através do sistema, se tornando grande tão rapidamente que é difícil resolvê-la antes que haja uma queda geral.
Na época de nossa queda, tínhamos uma central de dados ativa (com componentes internos agindo como backup). Precisávamos da habilidade de transferir manualmente para uma nova central de dados quando um problema causasse uma queda na central existente. Nossa primeira prioridade foi garantir que tivéssemos um backup distribuível da Roblox, assim construiríamos esse backup na nova central de dados, localizada em uma região geográfica diferente. Essa proteção foi adicionada para os piores casos: uma queda se espalhando para componentes suficientes dentro de uma central de dados que a tornariam inoperável. Agora, temos uma central de dados gerenciando trabalhos (ativa) e uma de plantão, servindo como backup (passiva). Nosso objetivo a longo prazo é mover dessa configuração ativa-passiva pra uma configuração ativa-ativa, em que ambas as centrais de dados gerenciem a carga de trabalho, com um balanceador de carga distribuindo solicitações entre elas com base em latência, capacidade e saúde. Uma vez definida, esperamos ter uma confiabilidade ainda maior para todos da Roblox, e poderemos fazer transições instantâneas em vez de em horas.
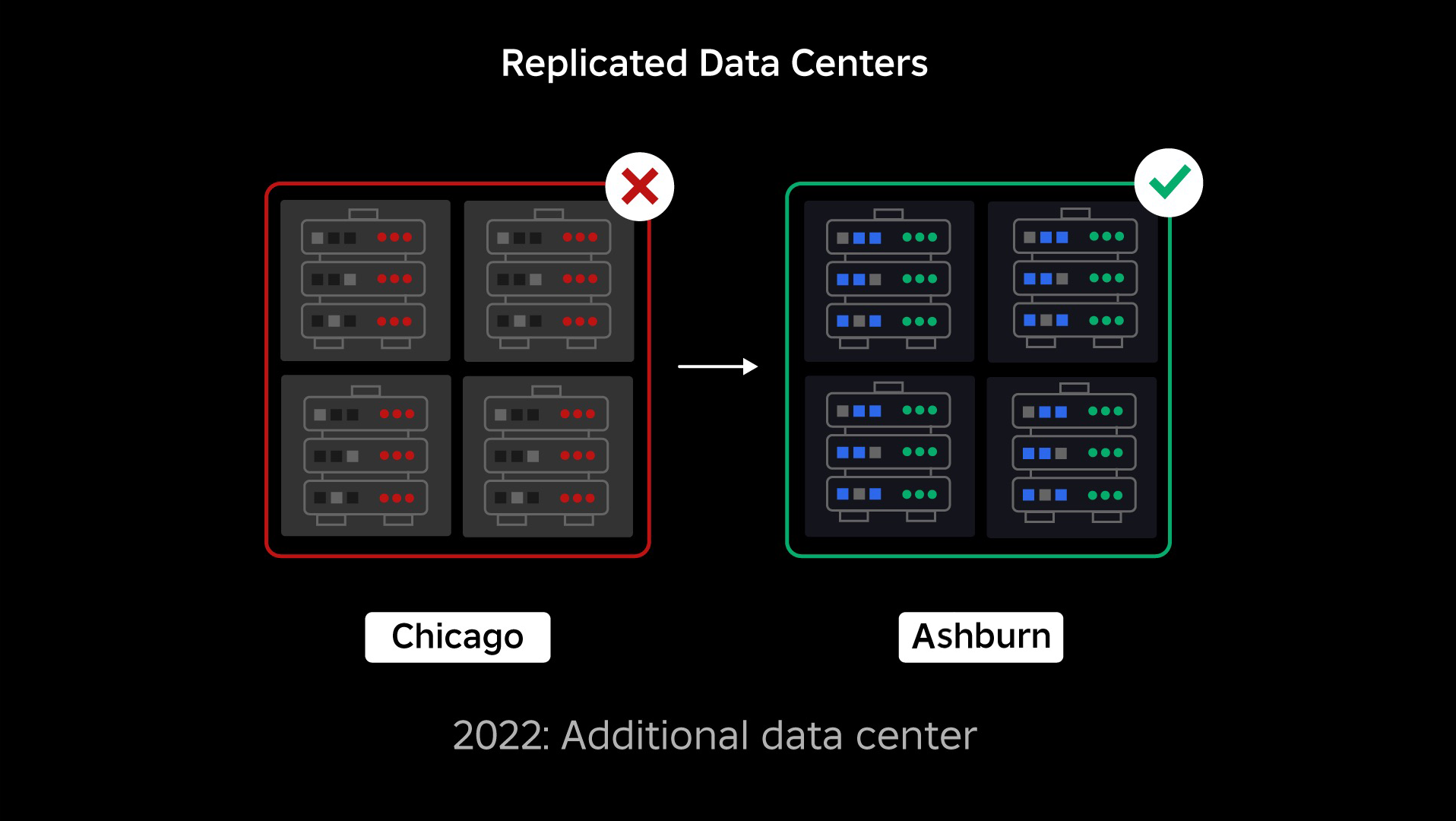
Movendo para uma infraestrutura celular
Nossa próxima prioridade era criar uma muralha dentro de cada central de dados para reduzir a possibilidade de um central de dados inteira falhar. Células (algumas empresas as chamam de clusters ou aglomerados) são essencialmente conjuntos de máquinas e é com elas que estamos criando essas muralhas. Replicamos serviços tanto dentro como através das células para redundância adicional. No fim das contas, queremos que todos os serviços da Roblox sejam executados em células, sendo beneficiados tanto por muralhas como por redundância. Se uma célula não é mais funcional, ela pode ser desativada seguramente. Replicação entre células permite que o serviço continue sendo executado enquanto células são reparadas. Em alguns casos, o reparo de uma célula pode significar uma substituição completa da célula. Na indústria, formatar e substituir uma máquina única ou um pequeno grupo de máquinas é bem comum, mas fazer isso para uma célula inteira – que contém até 1400 máquinas, não é.
Para isso funcionar, essas células precisam ser largamente uniformes, assim podemos mover cargas de trabalho de forma rápida e eficiente de uma célula para outra. Definimos certos requerimentos que os serviços precisam antes de ser executados em uma célula. Por exemplo, serviços precisam ser contidos, o que os tornam muito mais portáteis e previnem qualquer um de fazer mudanças de configuração ao nível de sistema operacional. Adotamos uma filosofia de infraestrutura-como-código para células: Em nosso repositório de código-fonte, incluímos a definição de tudo que está em uma célula, assim podemos reconstrui-la rapidamente a partir do zero usando ferramentas automáticas.
Nem todos os serviços cumprem esses requisitos, então trabalhamos para ajudar proprietários de serviços a cumpri-los onde possível e construímos novas ferramentas para tornar mais fácil a migração de serviços em células quando estiverem prontos. Por exemplo, nossa nova ferramenta de distribuição “arranca” automaticamente uma distribuição de serviços entre células, assim os proprietários de serviços não precisam pensar em estratégias de replicação. O nível de rigor torna o processo de migração muito mais desafiador e moroso, mas a recompensa é um sistema onde:
- É muito mais fácil conter uma falha e prevenir seu espalhamento para outras células;
- Nossos engenheiros de infraestrutura podem ser mais eficientes e se mover muito mais rápido; e
- Os engenheiros que construíram os serviços a nível de produto que são distribuídos nas células não precisam se preocupar ou saber em que células seus serviços estão sendo executados.
Resolvendo desafios maiores
Similar à maneira como portas anti-incêndio são usadas para conter chamas, células agem como muralhas dentro de nossa infraestrutura para ajudar a conter quaisquer problemas que estejam iniciando uma falha dentro de uma única célula. Com o tempo, todos os serviços que são parte da Roblox serão distribuídos de forma redundante dentro e entre células. Uma vez que esse trabalho esteja completo, problemas ainda podem se propagar o bastante para tornar uma célula inoperável, mas seria muito difícil para que um problema se propagasse além da célula afetada. E se nós sucedermos em tornar as células intercambiáveis, a recuperação será significativamente mais rápida, pois poderemos mover para uma célula diferente e evitaremos que o problema afete usuários finais.
O que pode ser complicado é separar essas células o suficiente para reduzir a oportunidade de propagação de erros, ao mesmo tempo em que mantemos tudo funcional. Em um sistema de infraestrutura complexo, serviços precisam se comunicar para compartilhar solicitações, informações, cargas de trabalho etc. À medida que replicamos esses serviços nas células, precisamos ser cuidadosos em como gerenciamos intercomunicação. Em um mundo ideal, redirecionamos tráfego de uma célula afetada para outras células saudáveis. Mas como podemos gerencias uma “solicitação de morte” – uma que está afetando uma célula negativamente? Se redirecionarmos essa solicitação para outra célula, ela pode afetar a próxima célula da mesma maneira que estamos tentando evitar. Precisamos encontrar mecanismos para divertir o tráfego “bom” de uma célula afetada ao mesmo tempo em que detectamos e diminuímos o tráfego que está afetando as células.
No curto prazo, estamos distribuindo cópias dos serviços de comunicação para cada célula computacional, assim a maioria das solicitações da central de dados podem ser servidas por uma única célula. Também estamos balanceando tráfego entre células. Olhando ainda mais à frente, estamos começando a construir a próxima geração de processos de descoberta de serviços que será alavancada por uma rede de serviços que esperamos completar em 2024. Isso vai nos permitir implementar políticas sofisticadas que permitirão comunicação entre células somente quando isso não afetar negativamente as células de salvaguarda. E em 2024, haverá um método de direcionar solicitações dependentes para uma versão de um serviço na mesma célula, o que minimizarão tráfego entre células e em seguida reduzirá o risco de propagação de falhas entre células.
Em momentos de pico, mais de 70% de nosso serviço de tráfego de back-end é servido por células e estamos aprendendo muito sobre como criar células, mas antecipamos mais pesquisas e testes enquanto continuamos a migrar nossos serviços em 2024 e além. Enquanto progredimos, essas muralhas se tornarão mais e mais fortes.
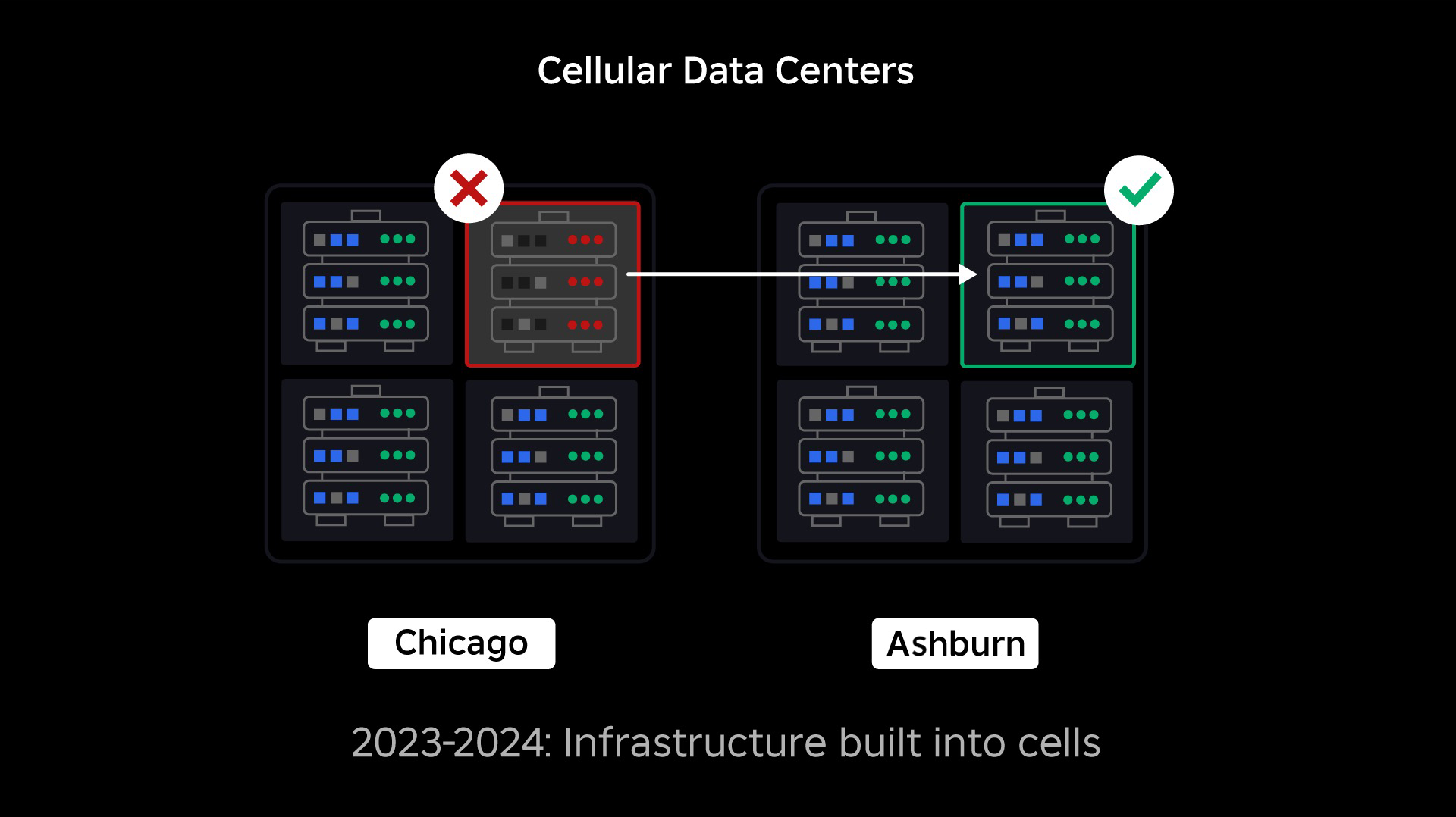
Migrando para um infraestrutura sempre ativa
A Roblox é uma plataforma global suportando usuários no mundo todo, então não podemos mover serviços durante períodos fora do pico ou de “baixa atividade”, o que complica o processo de migração de todas nossas máquinas em células e nossos serviços que são executados nessas células. Temos milhões de experiências sempre ligadas que precisam ser suportadas mesmo enquanto movemos as máquinas onde elas são executadas e os serviços que as suportam. Quando começamos esse processo, não tínhamos dezenas de milhares de máquinas sem uso e disponíveis para a migração das cargas de trabalho.
O que tínhamos era um pequeno número de máquinas adicionais que foram compradas antecipando futuros crescimentos. Para começar, construímos novas células usando essas máquinas, então migramos cargas de trabalho para elas. Valorizamos eficiência e confiabilidade, então em vez de comprar mais máquinas quando esgotamos nossas máquinas adicionais, construímos mais células formatando e reaproveitamos as máquinas de onde já tínhamos migrado. Em seguida, migramos cargas de trabalho para essas máquinas reaproveitadas e começamos o processo de novo. O processo é complexo, enquanto as máquinas são substituídas e liberadas para ser adicionadas às células, elas não são liberadas em uma ordem ideal. Elas são fisicamente fragmentadas entre corredores de dados, nos obrigando a reaproveitá-las aos poucos, o que requer um processo de desfragmentação ao nível de hardware para manter os locais de hardware alinhados com domínios de falhas físicas de larga escala.
Uma porção de nossa equipe de infraestrutura está focada em migrar cargas de trabalho existentes de nossos ambientes antigos (ou pré-células) para células. Esse trabalho irá continuar até que tenhamos migrado milhares de serviços de infraestruturas diferentes e milhares de serviços de back-end em novas células. A expectativa é que isso leve a maior parte do ano que vem e possivelmente parte de 2025, devido a alguns fatores complicadores. Primeiro, esse trabalho precisa que ferramentas robustas sejam construídas. Por exemplo, precisamos de ferramentas que balancem automaticamente grandes números de serviços quando distribuímos para uma nova célula – tudo isso sem impactar nossos usuários. Também estamos vendo serviços que foram construídos pensando em nossa infraestrutura. Precisamos revisar esses serviços para que eles não dependam de coisas que podem mudar no futuro quando os movermos para novas células. Também estamos implementando uma maneira de buscar designs conhecidos que não funcionarão bem com a arquitetura celular, bem como um processo de teste metódico para cada serviço que é migrado. Esses processos nos ajudam a evitar problemas para os usuários que possam ser causados por um serviço incompatível com células.
Hoje, cerca de 30 mil máquinas estão sendo gerenciadas por células. Isso é somente uma fração de nossa frota, mas tem sido uma transição bem tranquila até o momento, sem impacto negativo para os jogadores. Nosso objetivo final é que nossos sistemas possam alcançar 99,99% de tempo ativos de usuários por mês, significando que não romperíamos mais que 0,01% de horas de engajamento. Em geral na indústria, quedas não podem ser eliminadas completamente, mas nosso objetivo é reduzir quaisquer quedas da Roblox a um nível quase imperceptível.
Preparando-se para o futuro enquanto escalamos
Enquanto nossos esforços iniciais têm se provado bem-sucedidos, nosso trabalho nas células está longe de terminar. Enquanto a Roblox continua a escalar, estamos trabalhando para melhorar a efici6encia e resiliência de nossos sistemas através disso e de outras tecnologias. Enquanto continuamos, a plataforma vai se tornar mais e mais resiliente a problemas e quaisquer problemas que ocorrerem devem ser progressivamente menos visíveis e disruptivas para as pessoas em nossa plataforma.
Em resumo, até o momento, nós:
- Construímos uma segunda central de dados e alcançamos o status passivo/ativo com sucesso.
- Criamos células em nossas centrais de dados ativas e passivas e migramos com sucesso mais de 70% de nosso serviço de tráfego de back-end para essas células.
- Definimos os requisitos e boas práticas que precisamos seguir para manter todas nossas células uniformes enquanto migramos o resto de nossa infraestrutura.
- Iniciamos um processo contínuo de construir muralhas mais fortes entre células.
À medida que essas células se tornam mais intercambiáveis, haverá menos comunicação entre células. Isso desbloqueia oportunidades muito interessantes para nós em termos de aumento de automação em monitoramento, resolução de problemas e até mesmo transferência de cargas de trabalho de forma automática.
Em setembro, nós começamos a executar experimentos ativo/ativo em nossas centrais de dados. Esse é outro mecanismo que estamos testando para melhorar a confiabilidade e minimizar o tempo de troca. Esses experimentos têm ajudado a identificar um número de padrões de design de sistemas, muitos em acesso de dados, que precisamos refazer para que possamos ser totalmente ativo/ativo. Em geral, o experimento foi bem-sucedido o suficiente para que pudéssemos deixá-lo executando o tráfego de um número limitado de usuários.
Estamos ansiosos para continuar guiando este trabalho para trazer maior eficiência e resiliência para a plataforma. Este trabalho em células e infraestrutura ativa/ativa, juntamente com nossos outros esforços, tem tornado possível um crescimento de forma confiável e como uma utilidade de alta performance para milhões de pessoas e para continuar a escalar como trabalhamos para conectar um bilhão de pessoas em tempo real.