Roblox(ロブロックス)のインフラの効率化と耐久性向上への当社の取り組み
by Daniel Sturman, Chief Technology Officer; Max Ross, Vice President, Engineering; and Michael Wolf, Technical Director
テック
過去16年以上にわたるRobloxの成長と共に、何百万本もの没入感あふれる共有3Dバーチャル空間を支える技術インフラの規模と複雑さも増してきました。 当社がサポートしているマシンの数は、2021年6月30日時点の約36,000台から現在の約145,000台へと過去2年間で3倍以上に増加しています。 世界中の皆さんのために、こうした常時接続のバーチャル空間をサポートするには1,000を超える社内サービスが必要です。 コストとネットワークの遅延をコントロールするために、当社はこれらのマシンを主に構内で稼働するカスタムメイドのハイブリッドプライベートクラウドインフラの一部としてデプロイし、管理しています。
当社のインフラは、Robloxでの経済活動をあてにしているクリエーターの皆さんを含む、現在世界中で7000万人以上のデイリーアクティブユーザーを をサポートしています。 何百万人ものみなさんが非常に高いレベルの信頼性を期待しています。 当社のバーチャル空間が没入感のあるものであることを考えると、遅延や待ち時間に対する許容度は極めて低く、ましてや機能停止はありえないことです。 Robloxは、没入感のある3Dバーチャル空間の中で人々が集う、コミュニケーションとつながりのためのプラットフォームです。 没入感のある空間でアバターとしてコミュニケーションする場合、ちょっとした遅延や不具合も、テキストのスレッドや電話会議などよりも目立ってしまいます。
2021年10月、当社はシステム全体が停止するという事態を経験しました。 最初は小さな問題で、一ヶ所のデータセンターにあった一つのコンポーネントの問題から始まりました。 しかし、当社が調査している間に瞬く間に広がり、最終的には73時間のサービス中断となりました。 その時、当社は 何が起きたかの詳細 と問題から学んだ初期の洞察の一部を公開しました。 それ以来、当社はその教訓を研究し、極端なトラフィックの急増、天候、ハードウェアの故障、ソフトウェアのバグ、あるいは単純な人間によるミスなど、あらゆる大規模システムで発生するタイプの障害に対するインフラの耐障害性を高める努力をしてきました。 このような故障が発生した場合、1つのコンポーネント、あるいはコンポーネント群の問題がシステム全体に波及しないようにするにはどうすればいいのでしょうか。 この疑問は過去2年間、当社が焦点を当ててきたものであり、その作業は現在も進行中ですが、これまでに成し遂げてきたことはすでに実を結びつつあります。 例えば、2023年上半期には2022年上半期と比較して月間1億2500万エンゲージメント時間を節約しました。 今日は、当社がすでに行ってきた仕事と、さらに耐久性のあるインフラシステムを構築するための長期的なビジョンをお伝えします。
バックストップの構築
大規模なインフラシステムでは、小規模な障害は1日に何度も起こります。 1台のマシンに問題が発生し、サービスを停止しなければならなくなったとしても、ほとんどの企業がバックエンド・サービスで複数のインスタンスを維持しているため管理することは可能です。 そのため、1つのインスタンスに障害が発生しても、他のインスタンスが作業負荷を補います。 このような頻繁な不具合に対処するため、リクエストは一般にエラーが発生したら自動的に再試行するように設定されています。
システムや人があまりに積極的に再試行すると、小規模な障害がインフラ全体に伝播し、他のサービスやシステムに影響を及ぼす可能性があります。 ネットワークやユーザーが十分にしつこく再試行すれば、最終的にはそのサービスのすべてのインスタンス、そして潜在的には他のシステムに、世界規模で過負荷をかけることになります。 当社の2021年の障害は、大規模システムではよくあることの結果でした。障害は小さなものから始まり、システム全体に伝播し、あっという間に大きくなり、すべてが停止する前に解決するのは難しいです。
障害発生時、当社にはアクティブなデータセンターが1つありました(その中のコンポーネントがバックアップとして機能していました)。 問題が発生して既存のデータセンターがダウンした場合、新しいデータセンターに手動でフェイルオーバーする機能が必要でした。 当社がまず優先したのはRobloxのバックアップを確保することだったため、 別の地域にある新しいデータセンターにバックアップを構築しました。 これは、最悪のシナリオ、つまりデータセンター内の十分な数のコンポーネントにサービス中断が広がり、データセンターが完全に機能しなくなるという事態を想定したものです。 現在、1つのデータセンターがワークロードを処理し(アクティブ)、もう1つはスタンバイでバックアップの役割を担っています(パッシブ)。 当社の長期的な目標は、このアクティブパッシブ構成からアクティブアクティブ構成に移行することです。両方のデータセンターが作業負荷を処理し、負荷バランサーが遅延、容量、健全性に基づいてリクエストをデータセンター間で分散します。 これが導入されれば、Roblox全体の信頼性がさらに高まり、フェイルオーバーも数時間ではなく、ほぼ瞬時に行えるようになると期待しています。
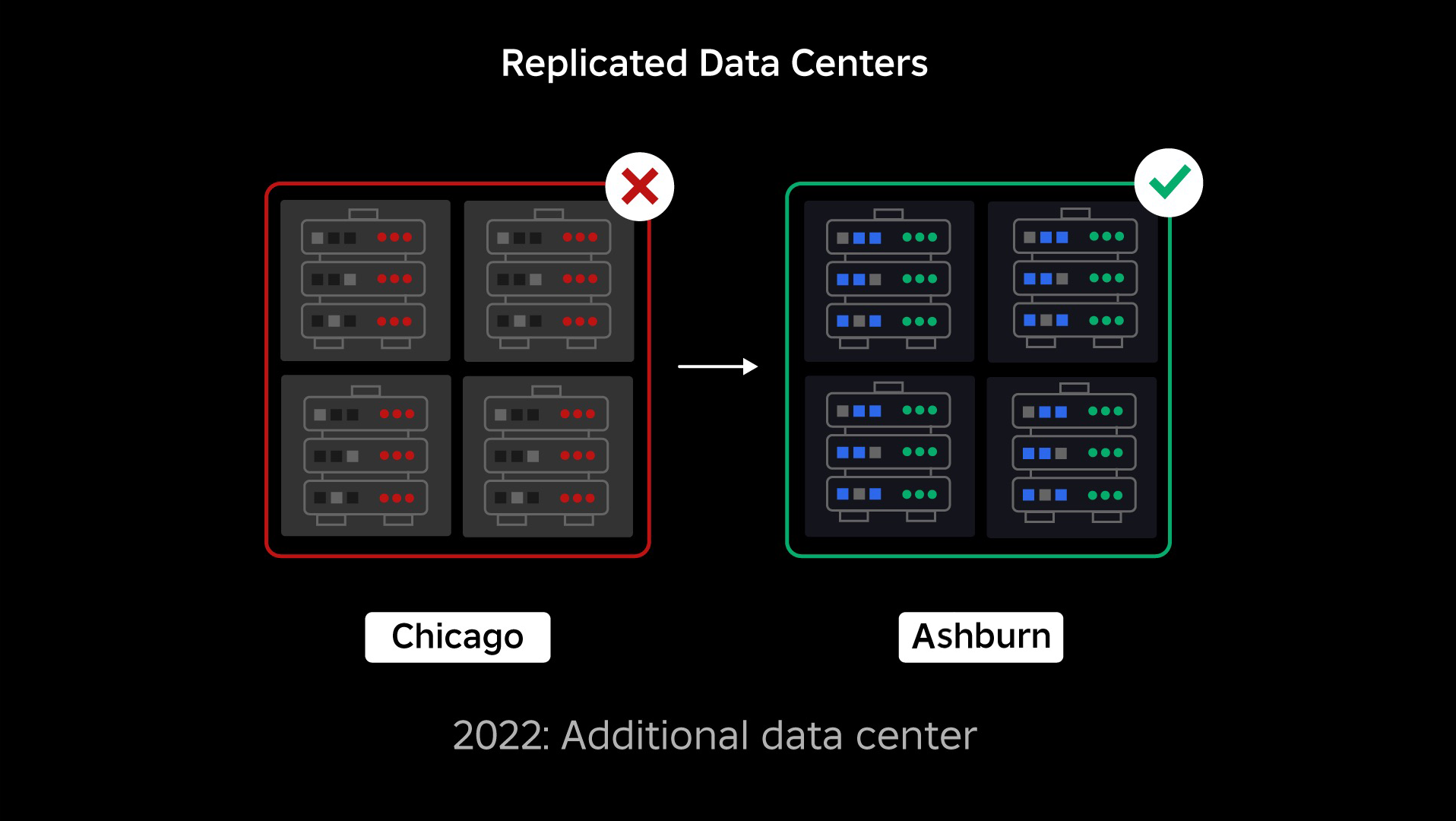
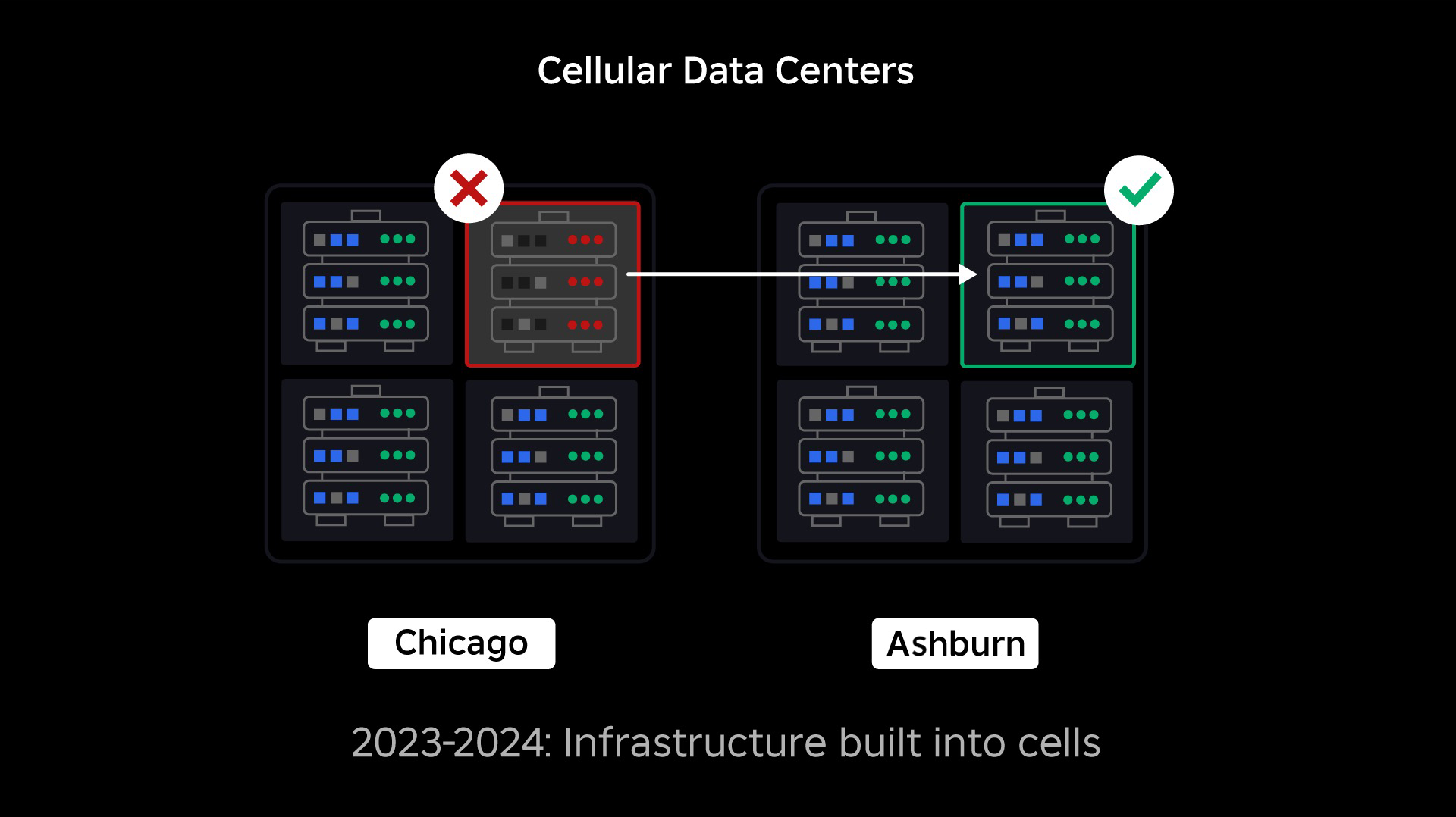
セル方式インフラへの移行
当社が次に優先したのは、データセンター全体が機能不全に陥る可能性を減らすため、各データセンター内に強固なブラストウォールを作ることでした。 セル(クラスターと呼ぶ企業もある)は基本的にマシンの集合体であり、当社はこうやって壁を作っています。 冗長性を高めるために、セル内とセル間の両方でサービスを複製しています。 最終的には、Robloxのすべてのサービスをセルで運営することで、強固なブラストウォールと冗長性の両方のメリットを享受できるようにしたいと考えています。 セルが機能しなくなれば、安全に機能停止させることができます。 セルをまたいだレプリケーションによって、セルを修理している間もサービスを継続することができます。 場合によっては、セルの修復は細胞の完全な再生成を意味するかもしれません。 業界全体では、個々のマシンや小さな複数のマシンをワイプして再プロビジョニングすることはかなり一般的ですが、1,400台ものマシンを含むセル全体をワイプして再ビジョニングすることは一般的ではありません。
そのためには、セルがほぼ均一である必要があり、セル間で作業負荷を迅速かつ効率的に移動させることができます。 当社は、サービスがセル内で実行される前に満たす必要のある一定の要件を設定しています。 例えば、サービスはコンテナ化されなければなりませんが、これによって移植性が格段に向上し、OSレベルでの設定変更を誰でも行えるようになります。 当社はセルに「インフラストラクチャー・アズ・コード」という哲学を採用しています。当社のソースコード・リポジトリには、セル内のすべての定義が含まれているので、自動化ツールを使ってゼロから素早く再構築することができます。
現在、すべてのサービスがこれらの要件を満たしているわけではないので、可能な限りサービスオーナーが要件を満たせるよう支援し、準備が整えば簡単にサービスをセルに移行できるように新しいツールを構築ししました。 例えば、鳥栖亜hの新しいデプロイメント・ツールは、セル間でサービス・デプロイメントを自動的に「ストライピング」するので、サービス所有者はレプリケーション戦略を考える必要がありません。 このレベルの厳密さは、移行プロセスをより困難で時間のかかるものにしているが、長期的な見返りは以下のようなシステムです。
- 故障を封じ込め、他のセルに広がるのを防ぐ方がはるかに簡単です。
- インフラエンジニアはより効率的に、より迅速に行動できます。
- 最終的にセルに配備される製品レベルのサービスを構築するエンジニアは、そのサービスがどのセルで実行されているかを知る必要も心配する必要もありません。
さらに大規模な課題の解決
防火扉が炎を封じ込めるのに使われるのと同じように、セルはインフラ内で強力な防風壁として機能し、故障の引き金となる問題を1つのセル内に封じ込めるのに役立ちます。 最終的には、Robloxを構成するすべてのサービスは、セル内およびセル間で冗長的に展開されることになります。 この作業が完了しても、セル全体を使用不能にするほど広範囲に問題が伝播する可能性はありますが、そのセルを超えて問題が伝播することは極めて困難です。 また、セルを交換可能にすることに成功すれば、別のセルにフェイルオーバーしてエンドユーザーに影響を与えないようにできるため、リカバリーが大幅に速くなる。
これが厄介なのは、エラーの伝播の機会を減らしつつ、パフォーマンスと機能性を維持するために、これらのセルを十分に分離することです。 複雑なインフラシステムでは、サービス同士がクエリ、情報、作業負荷などを共有するために通信する必要があります。 これらのサービスをセル内に複製するときは、相互通信をどのように管理するかについて熟慮する必要があります。 理想的な世界では、ある不健康なセルから他の健康なセルへとトラフィックを振り分けます。 しかし、セルを不健全にする 原因となる 「死のクエリ」 にどう対処すればいいのでしょうか? そのクエリを別のセルにリダイレクトすれば、当社が避けようとしているように、そのセルが不健康になる可能性があります。 当社は、不健康なセルから「良い」トラフィックをシフトさせ、同時にセルを不健康にする原因となるトラフィックを検出し、抑制するメカニズムを見つける必要があります。
短期的には、各コンピュートセルにコンピューティングサービスのコピーを配備し、データセンターへのリクエストのほとんどを1つのセルで処理できるようにした。 また、セル間のトラフィックの負荷分散も行っています。 さらに先を見据えて、サービス・メッシュで活用される次世代のサービス発見プロセスの構築に着手しており、2024年の完成を目指しています。 これにより、フェイルオーバーセルに悪影響を与えない場合にのみ、セル間の通信を許可するような高度なポリシーを実装することができます。 また、2024年には、依存するリクエストを同じセル内のサービス・バージョンに向ける方法も登場する予定です。これは、クロスセルのトラフィックを最小化し、それによって障害のクロスセル伝搬のリスクを低減させます。
ピーク時には、バックエンドのサービス・トラフィックの70%以上がセルから提供されており、セルの作成方法について多くのことを学びました。しかし、2024年以降もサービスの移行を続ける中で、さらなる研究とテストが必要になると予想しています。 当社が前進するにつれて、このブラストウォールはますます強固になっていきます。
常時稼働インフラの移行
Robloxは世界中のユーザーをサポートするグローバルなプラットフォームなので、オフピークや「ダウンタイム」にサービスを移動させることはできません。そのため、すべてのマシンをセルに移行し、そのセルで稼働するサービスを移行するプロセスがさらに複雑になります。 何百万もの常時接続のバーチャル空間をがあり、これらが動作するマシンやそれを支えるサービスを移動させても、サポートし続ける必要があります。 このプロセスを開始したとき、作業負荷を移行するために何万台ものマシンが使われずに放置されていたわけではありません。
しかし、将来の成長を見越して購入した追加マシンの数は少ないものでした。 手始めに、これらのマシンを使って新しいセルを構築し、作業負荷を移行しました。 当社は信頼性だけでなく効率も重視しているので、「予備」のマシンがなくなったらマシンを買い足すのではなく、移行したマシンを消去して再プロビジョニングすることでセルを増やしました。 その後、再プロビジョニングされたマシンに作業負荷を移行し、プロセスを最初からやり直しました。 このプロセスは複雑です。マシンが入れ替わり、セルの中に組み込まれるようになりますが理想的で整然とした形でマシンが解放されるわけではないからです。 これらは物理的にデータホール間で断片化されているため、断片的な方法でプロビジョニングすることになります。そのため、ハードウェアのロケーションを大規模な物理障害ドメインと一致させるために、ハードウェアレベルのデフラグ処理が必要となります。
当社のインフラ・エンジニアリング・チームの一部は、レガシー環境、つまり「セル以前」の環境から既存のワークロードをセルに移行することに注力しています。 この作業は、何千ものさまざまなインフラサービスと何千ものバックエンド・サービスを新しく構築されたセルに移行するまで続きます。 複雑な要因があるため、来年いっぱい、場合によっては2025年までかかると予想しています。 第一に、この作業には堅牢なツールの構築が必要です。 例えば、新しいセルを導入する際に、ユーザーに影響を与えることなく、大量のサービスのバランスを自動的に調整するツールが必要です。 当社のインフラを前提に作られたサービスも見てきました。 当社は、これらのサービスを、将来セルに移行する際に変わる可能性のあるものに依存しないように見直す必要があります。 また、セルラー・アーキテクチャーではうまく機能しない既知のデザイン・パターンを検索する方法と、移行される各サービスに対する体系的なテスト・プロセスの両方を実装しました。 これらのプロセスは、セルと互換性のないサービスに起因するユーザーとの問題を回避するのに役立ちます。
今日、3万台近いマシンがセルによって管理されています。 これは当社の全フリートのほんの一部に過ぎませんが、プレイヤーへの悪影響もなく、今のところ非常にスムーズに移行できています。 当社の究極の目標は、システムが毎月99.99パーセントのユーザー・アップタイムを達成することです。これは、エンゲージメント時間の0.01パーセントを超えないことを意味します。 業界全体として、ダウンタイムを完全になくすことはできませんが、当社の目標は、Robloxのダウンタイムをほとんど気づかれない程度まで減らすことです。
規模拡大に伴う将来への備え
当社の初期の努力は成功を収めつつありますが、セルに関する当社の作業はまだ終わっていません。 Robloxが規模を拡大し続ける中、当社はこの技術やその他の技術を通じて、システムの効率性と耐障害性を向上させる努力を続けていきます。 そうしていくうちに、プラットフォームは問題に対してますます強くなり、発生した問題は徐々に目立たなくなり、プラットフォームを利用する人々への混乱も少なくなっていくはずです。
まとめると、当社が現在まで達成したことは以下のことです。
- 2つ目のデータセンターを構築し、アクティブパッシブ・ステータスの獲得に成功しました。
- 当社のアクティブおよびパッシブ・データセンターにセルを作成し、バックエンド・サービスのトラフィックの70%以上をこれらのセルに移行することに成功しました。
- 残りのインフラ移行を続けるに際して、すべてのセルを統一するために必要な要件とベストプラクティスを設定します。
- セル間の「ブラストウォール」をより強固にする継続的なプロセスを開始しました。
これらのセルの互換性が高まれば、セル間のクロストークは少なくなります。 監視やトラブルシューティング、さらには作業負荷の自動シフトなど、自動化を進めるという点で、当社にとって非常に興味深い機会が開かれています。
9月には、データセンター全体でアクティブアクティブの実験も開始しました。 これは信頼性を向上させ、フェイルオーバー時間を最小化するために当社がテストしているもうひとつのメカニズムです。 これらの実験により、完全なアクティブ・アクティブ化を進めるにあたり、当社が手直しする必要がある主にデータアクセスにまつわるシステム設計パターンをいくつか特定することができました。 全体的にこの実験は、限られた数のユーザーのトラフィックのために稼働させるのに十分で成功しました。
当社は、より効率的で弾力性のあるプラットフォームを実現するため、この作業を推進していくことにワクワクしています。 セルとアクティブ・アクティブ・インフラに関するこの取り組みは、他の取り組みとともに、当社が何百万人もの人々にとって信頼できる高性能の公益事業へと成長することを可能にし、10億人をリアルタイムで接続するための取り組みとして拡張し続けることを可能にしています。