Briser les barrières linguistiques grâce à un modèle de traduction multilingue
by Daniel Sturman, Chief Technology Officer
Technologie
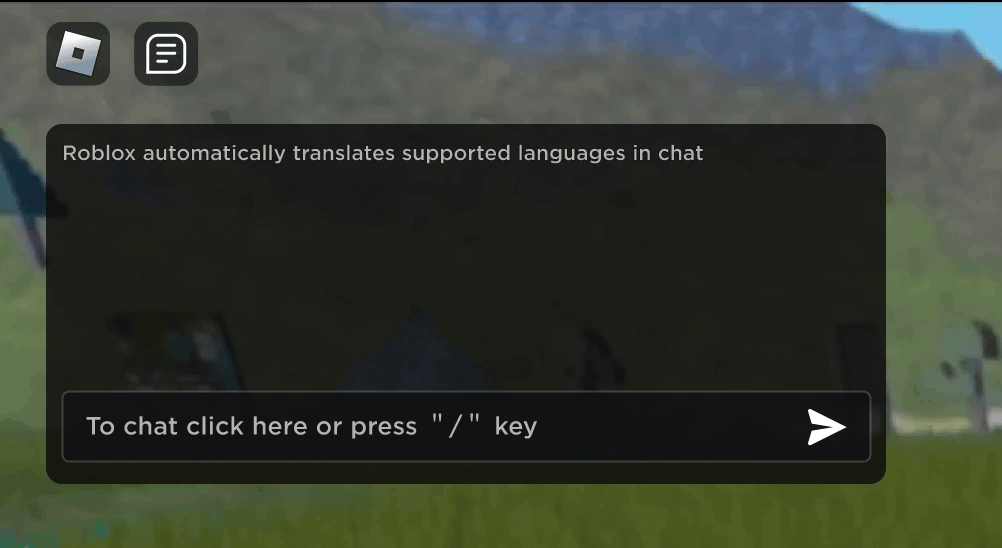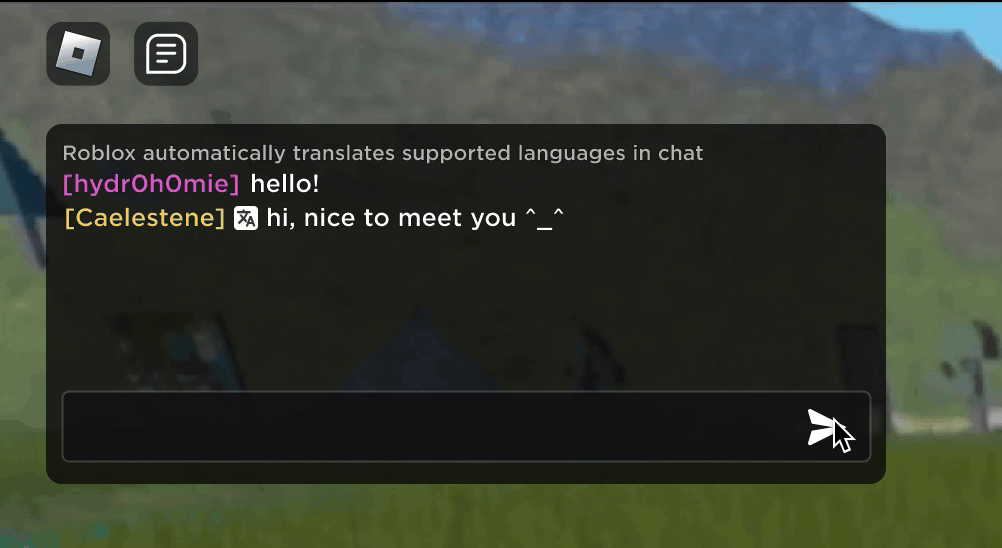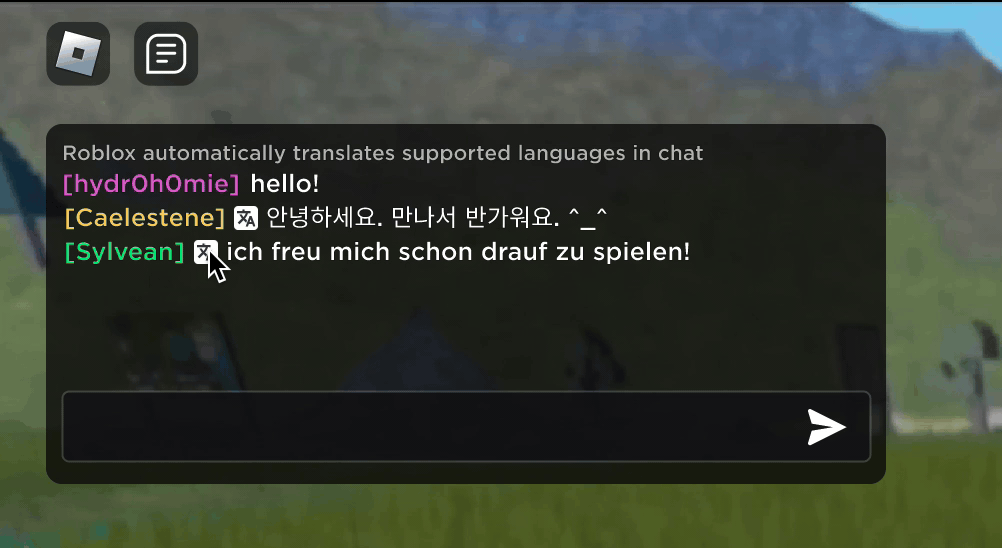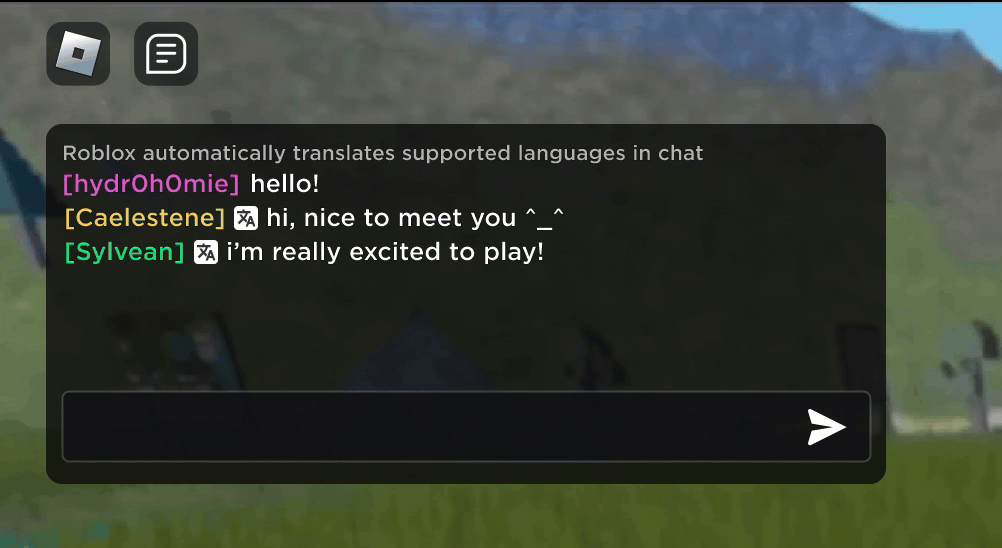
Imaginez que vous découvriez que votre nouvel ami Roblox, une personne avec laquelle vous avez discuté et plaisanté dans une nouvelle expérience, se trouve en fait en Corée – et qu’il a tapé en coréen pendant tout ce temps, tandis que vous tapiez en anglais, sans qu’aucun de vous ne le remarque. Grâce à nos nouvelles traductions de chat par IA en temps réel, nous avons rendu possible sur Roblox quelque chose qui n’est même pas possible dans le monde physique : permettre à des personnes parlant des langues différentes de communiquer entre elles de manière transparente dans nos expériences immersives en 3D. Cela est possible grâce à notre modèle multilingue large (LLM) personnalisé, qui permet désormais une traduction directe entre n’importe quelle combinaison des 16 langues que nous prenons actuellement en charge (ces 15 langues, ainsi que l’anglais).
Dans toutes les expériences qui ont activé notre service de chat textuel intégré dans l’expérience, les personnes de différents pays peuvent désormais être comprises par des personnes qui ne parlent pas leur langue. La fenêtre de chat affichera automatiquement le coréen traduit en anglais, ou le turc traduit en allemand, et vice versa, de sorte que chaque personne voit la conversation dans sa propre langue. Ces traductions sont affichées en temps réel, avec une latence d’environ 100 millisecondes, de sorte que la traduction qui se produit en coulisses est pratiquement invisible. L’utilisation de l’IA pour automatiser les traductions en temps réel dans les chats textuels permet d’éliminer les barrières linguistiques et de rapprocher les gens, où qu’ils vivent dans le monde.
Construire un modèle de traduction unifié
La traduction par l’IA n’est pas nouvelle, la majorité de notre contenu d’expérience est déjà traduite automatiquement. Nous voulions aller au-delà de la traduction du contenu statique dans les expériences. Nous voulions traduire automatiquement les interactions – et nous voulions le faire pour les 16 langues que nous prenons en charge sur la plateforme. Il s’agissait d’un objectif audacieux pour deux raisons : Tout d’abord, nous ne nous contentions pas de traduire d’une langue principale (l’anglais) à une autre, nous voulions une traduction complète 16×16. Deuxièmement, la traduction devait être rapide. Suffisamment rapide pour prendre en charge de véritables conversations en ligne, ce qui signifie pour nous une latence d’environ 100 millisecondes.
Roblox compte plus de 70 millions d’utilisateurs actifs quotidiens dans le monde entier, et ce chiffre ne cesse de croître. Les gens communiquent et créent sur notre plateforme – chacun dans sa langue maternelle – 24 heures par jour. Il n’est évidemment pas possible de traduire manuellement toutes les conversations qui se déroulent sur plus de 15 millions d’expériences actives, et ce en temps réel. L’extension de ces traductions en direct avec des millions de personnes, qui ont toutes des conversations différentes dans des expériences différentes simultanément, nécessite un LLM d’une rapidité et d’une précision extraordinaires. Nous avons besoin d’un modèle contextuel qui reconnaisse le langage spécifique à Roblox, y compris l’argot et les abréviations (comme obby, stp ou mdr). En outre, notre modèle doit prendre en charge toutes les combinaisons des 16 langues actuellement prises en charge par Roblox.
Pour ce faire, nous aurions pu construire un modèle unique pour chaque paire de langues (par exemple, le japonais et l’espagnol), mais cela aurait nécessité un ensemble 16×16, soit 256 modèles différents. Au lieu de cela, nous avons construit un LLM de traduction unifié, basé sur des transformateurs, et appliqué une architecture de mixage d’experts. C’est comme si vous disposiez de plusieurs applications de traduction, chacune spécialisée dans un groupe de langues similaires, toutes disponibles avec une interface unique. À partir d’une phrase source et d’une langue cible, nous pouvons activer l’expert approprié pour générer les traductions.
Cette architecture permet une meilleure utilisation des ressources, puisque chaque expert a une spécialité différente, ce qui permet une formation et une inférence plus efficaces – sans sacrifier la qualité de la traduction.
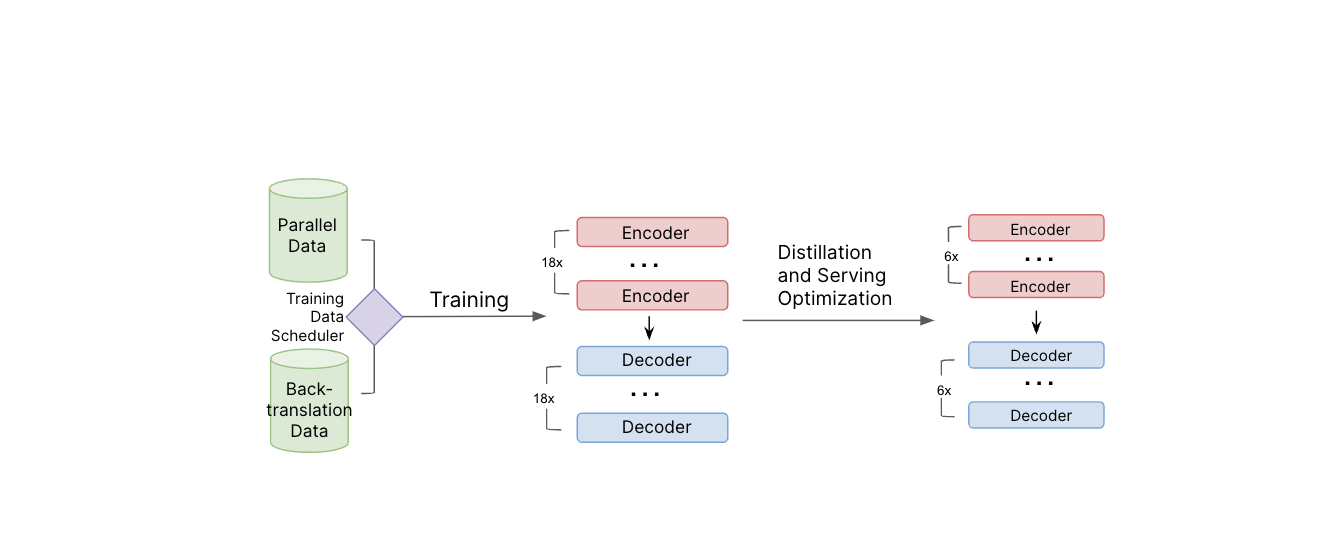
Illustration du processus d’inférence. Les messages source, ainsi que la langue source et les langues cibles, passent par le RCC (Roblox Compute Cloud). Avant d’atteindre le back-end, nous vérifions d’abord le cache pour voir si nous avons déjà des traductions pour cette demande. Si ce n’est pas le cas, la demande est transmise au back-end et au serveur de modèle avec une mise en lot dynamique. Nous avons ajouté une couche de cache d’intégration entre les codeurs et les décodeurs pour améliorer encore l’efficacité lors de la traduction dans plusieurs langues cibles.
Cette architecture rend la formation et la maintenance de notre modèle beaucoup plus efficaces, et ce pour plusieurs raisons. Tout d’abord, notre modèle est capable d’exploiter les similitudes linguistiques entre les langues. Lorsque toutes les langues sont traitées ensemble, les langues similaires, comme l’espagnol et le portugais, bénéficient de l’apport de l’autre pendant l’entraînement, ce qui permet d’améliorer la qualité de la traduction dans les deux langues. Nous pouvons également tester et intégrer beaucoup plus facilement les nouvelles recherches et avancées en matière de LLM dans notre système au fur et à mesure de leur publication, afin de bénéficier des techniques les plus récentes et les plus performantes. Nous constatons un autre avantage de ce modèle unifié dans les cas où la langue source n’est pas définie ou est définie de manière incorrecte, lorsque le modèle est suffisamment précis pour détecter la langue source correcte et traduire dans la langue cible. En fait, même si l’entrée comporte un mélange de langues, le système est toujours capable de détecter et de traduire dans la langue cible. Dans ce cas, la précision n’est peut-être pas aussi élevée, mais le message final sera raisonnablement compréhensible.
Pour entraîner ce modèle unifié, nous avons commencé par effectuer un pré-entraînement sur les données open source disponibles, ainsi que sur nos propres données de traduction, sur des résultats de traduction de chats étiquetés par des humains, et sur des phrases et des expressions de chat courantes. Nous avons également élaboré notre propre métrique d’évaluation de la traduction et notre propre modèle pour mesurer la qualité de la traduction. La plupart des mesures de qualité de traduction disponibles sur le marché comparent le résultat de la traduction par l’IA à une vérité de base ou à une traduction de référence et se concentrent principalement sur la compréhensibilité de la traduction. Nous voulions évaluer la qualitéqualité de la traduction, sans avoir recours à une traduction de référence.
Nous l’examinons sous plusieurs aspects, notamment l’exactitude (s’il y a des ajouts, des omissions ou des erreurs de traduction), la fluidité (ponctuation, orthographe et grammaire) et les références incorrectes (divergences avec le reste du texte). Nous classons ces erreurs par niveau de gravité : S’agit-il d’une erreur critique, majeure ou mineure ? Afin d’évaluer la qualité, nous avons construit un modèle de ML et l’avons entraîné sur des types d’erreurs et des scores labellisés par l’homme. Nous avons ensuite affiné un modèle linguistique multilingue pour prédire les erreurs et les types de mots et calculer un score à l’aide de nos critères multidimensionnels. Cela nous permet d’avoir une vision globale de la qualité et des types d’erreurs qui se produisent. Nous pouvons ainsi estimer la qualité de la traduction et détecter les erreurs en utilisant le texte source et les traductions automatiques, sans avoir besoin d’une traduction de référence. Les résultats de cette mesure de la qualité nous permettent d’améliorer la qualité de notre modèle de traduction.
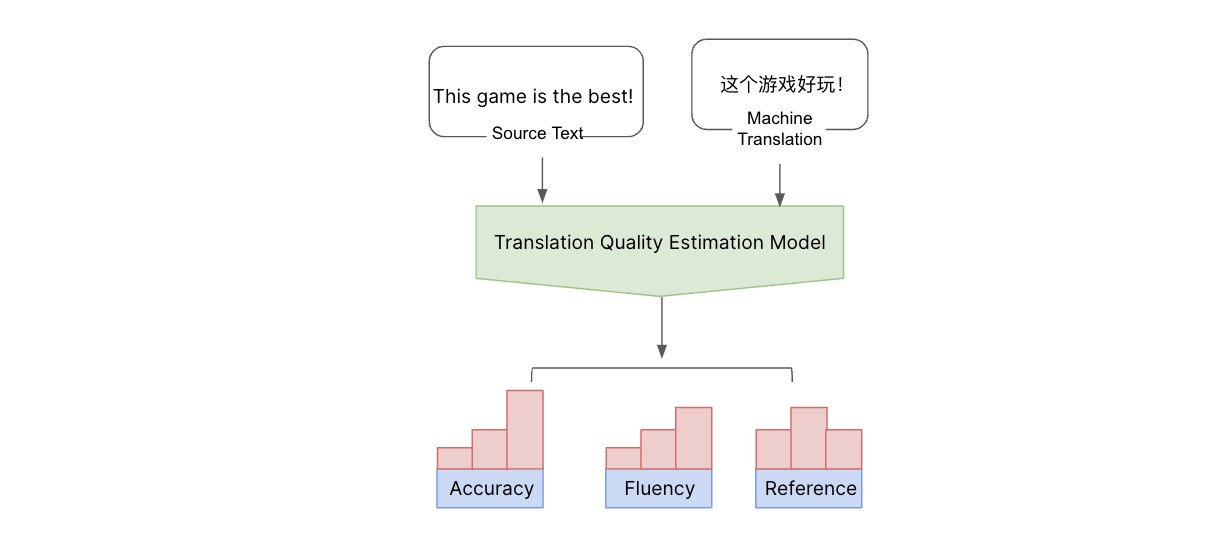
Avec le texte source et le résultat de la traduction automatique, nous pouvons estimer la qualité de la traduction automatique sans traduction de référence, en utilisant notre modèle interne d’estimation de la qualité de la traduction. Ce modèle estime la qualité sous différents aspects et classe les erreurs en erreurs critiques, majeures et mineures.
Les paires de traductions moins courantes (par exemple, du français au thaï) posent un problème en raison du manque de données de haute qualité. Pour combler cette lacune, nous avons appliqué la rétro-traduction, où le contenu est retraduit dans la langue d’origine, puis comparé au texte source pour en vérifier l’exactitude. Au cours du processus d’apprentissage, nous avons utilisé la rétrotraduction itérative, c’est-à-dire un mélange stratégique de ces données rétrotraduites et de données supervisées (étiquetées) afin d’augmenter la quantité de données de traduction sur lesquelles le modèle peut s’appuyer pour apprendre.
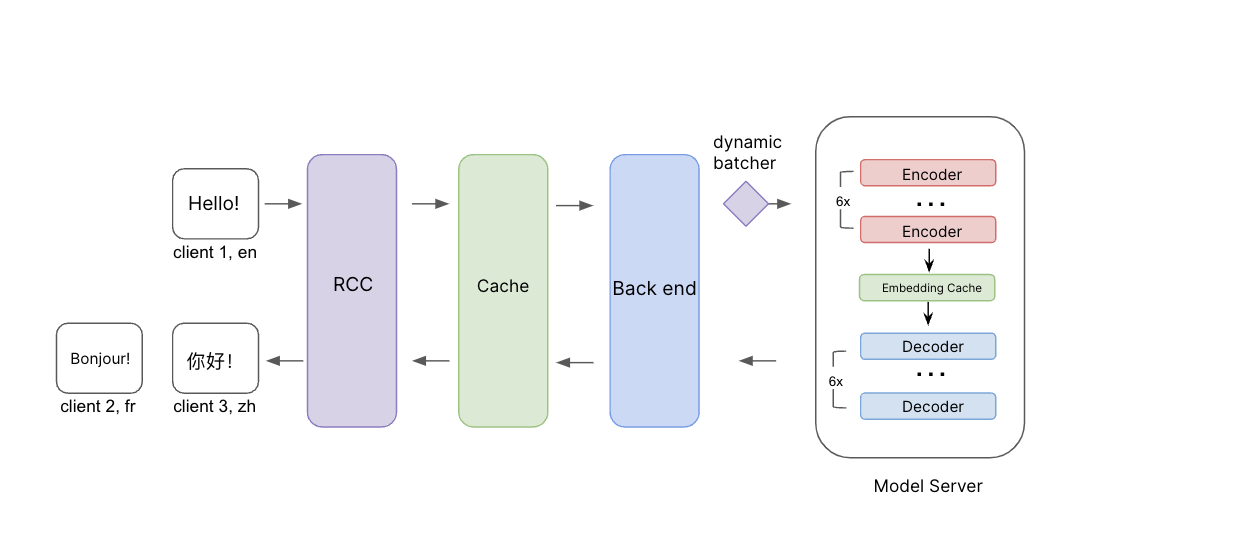
Illustration du pipeline de formation des modèles. Les données parallèles et les données de rétrotraduction sont utilisées lors de l’apprentissage du modèle. Une fois le modèle de référence formé, nous appliquons la distillation et d’autres techniques d’optimisation du service afin de réduire la taille du modèle et d’améliorer l’efficacité du service.
Pour aider le modèle à comprendre l’argot moderne, nous avons demandé à des évaluateurs humains de traduire les termes populaires et en vogue dans chaque langue, et nous avons inclus ces traductions dans nos données de training. Nous continuerons à répéter ce processus régulièrement pour que le système reste au fait des dernières nouveautés en matière d’argot.
Le modèle de traduction de chat qui en résulte comporte environ 1 milliard de paramètres. L’exécution d’une traduction à l’aide d’un modèle de cette taille nécessite des ressources prohibitives pour être utilisée à grande échelle et prendrait beaucoup trop de temps pour une conversation en temps réel, où une faible latence est essentielle pour prendre en charge plus de 5 000 chats par seconde. Nous avons donc utilisé ce grand modèle de traduction dans une approche élève-enseignant pour construire un modèle plus petit et plus léger. Nous avons appliqué la distillation, la quantification, la compilation de modèles et d’autres optimisations de service pour réduire la taille du modèle à moins de 650 millions de paramètres et améliorer l’efficacité du service. En outre, nous avons modifié l’API qui sous-tend le chat textuel dans l’expérience afin d’envoyer les messages originaux et traduits sur l’appareil de la personne. Cela permet au destinataire de voir le message dans sa langue maternelle ou de passer rapidement au message original, non traduit, de l’expéditeur.
Une fois la version finale du LLM prête, nous avons mis en place un back-end pour se connecter aux serveurs du modèle. C’est à ce niveau que nous appliquons une logique de traduction supplémentaire et que nous intégrons le système à nos systèmes habituels de confiance et de sécurité. Le texte traduit est ainsi soumis au même niveau d’examen que le reste du texte, afin de détecter et de bloquer les mots ou les phrases qui enfreignent nos politiques. La sécurité et la civilité sont au premier plan de tout ce que nous faisons à Roblox, il s’agissait donc d’une pièce très importante du puzzle.
Améliorer en permanence la précision
In teLors des tests, nous avons constaté que ce nouveau système de traduction renforce l’engagement et la qualité des sessions pour les utilisateurs de notre plateforme. D’après nos propres mesures, notre modèle surpasse les API de traduction commerciales sur le contenu de Roblox, ce qui indique que nous avons réussi à optimiser la façon dont les gens communiquent sur Roblox. Nous sommes impatients de voir comment cela améliorera l’expérience des utilisateurs de la plateforme, en leur permettant de jouer à des jeux, de faire des achats, de collaborer ou simplement de prendre des nouvelles de leurs amis qui parlent une autre langue.
La possibilité pour les gens d’avoir des conversations fluides et naturelles dans leur langue maternelle nous rapproche de notre objectif de connecter un milliard de personnes avec optimisme et civilité.
Pour améliorer encore la précision de nos traductions et fournir à notre modèle de meilleures données d’entraînement, nous prévoyons de mettre en place un outil permettant aux utilisateurs de la plateforme de fournir un retour d’information sur leurs traductions et d’aider le système à s’améliorer encore plus rapidement. Cela permettrait aux utilisateurs de nous signaler les erreurs de traduction et même de suggérer une meilleure traduction que nous pourrions ajouter aux données d’entraînement afin d’améliorer encore le modèle.
Ces traductions sont disponibles aujourd’hui pour les 16 langues que nous prenons en charge, mais nous sommes loin d’avoir terminé. Nous prévoyons de continuer à mettre à jour nos modèles avec les derniers exemples de traduction issus de notre expérience, ainsi qu’avec les phrases de chat les plus populaires et les dernières expressions argotiques dans toutes les langues que nous prenons en charge. En outre, cette architecture permettra d’entraîner le modèle dans de nouvelles langues avec relativement peu d’efforts, au fur et à mesure que des données d’entraînement suffisantes seront disponibles pour ces langues. À plus long terme, nous étudions les moyens de traduire automatiquement tout ce qui est en plusieurs dimensions : texte sur des images, textures, modèles 3D, etc.
Et nous explorons déjà de nouvelles frontières passionnantes, notamment la traduction automatique messages vocaux . Imaginez qu’un francophone puisse dialoguer sur Roblox avec quelqu’un qui ne parle que le russe. Tous deux pourraient se parler et se comprendre, jusqu’au ton, au rythme et à l’émotion de leur voix, dans leur propre langue et avec une faible latence. Même si cela peut sembler relever de la science-fiction aujourd’hui, et qu’il faudra du temps pour y parvenir, nous continuerons à progresser dans le domaine de la traduction. Dans un avenir pas si lointain, Roblox sera un endroit où les gens du monde entier pourront communiquer de manière transparente et sans effort, non seulement par le biais d’un chat textuel, mais aussi dans toutes les modalités possibles !