Überwindung sprachlicher Barrieren mit einem mehrsprachigen Übersetzungsmodus
by Daniel Sturman, Chief Technology Officer
Tech
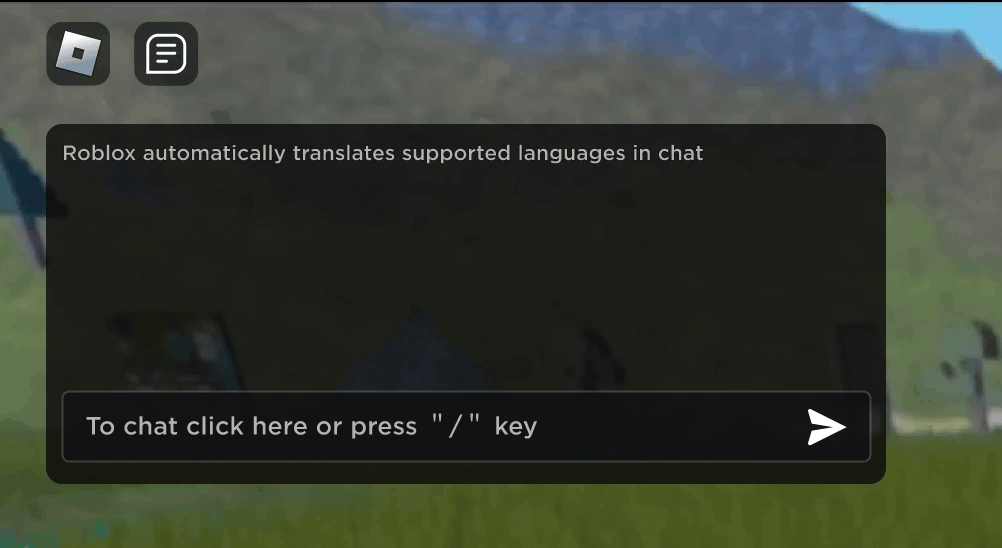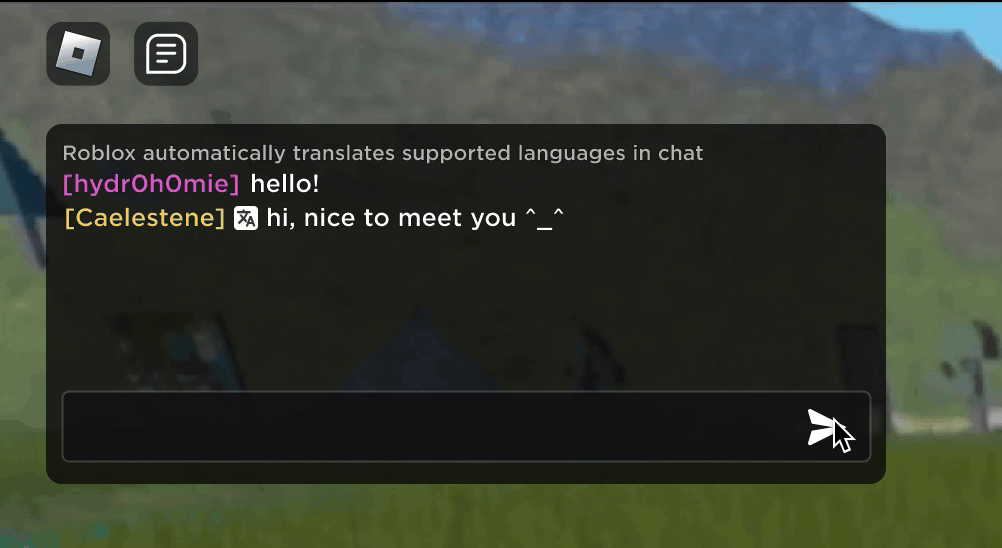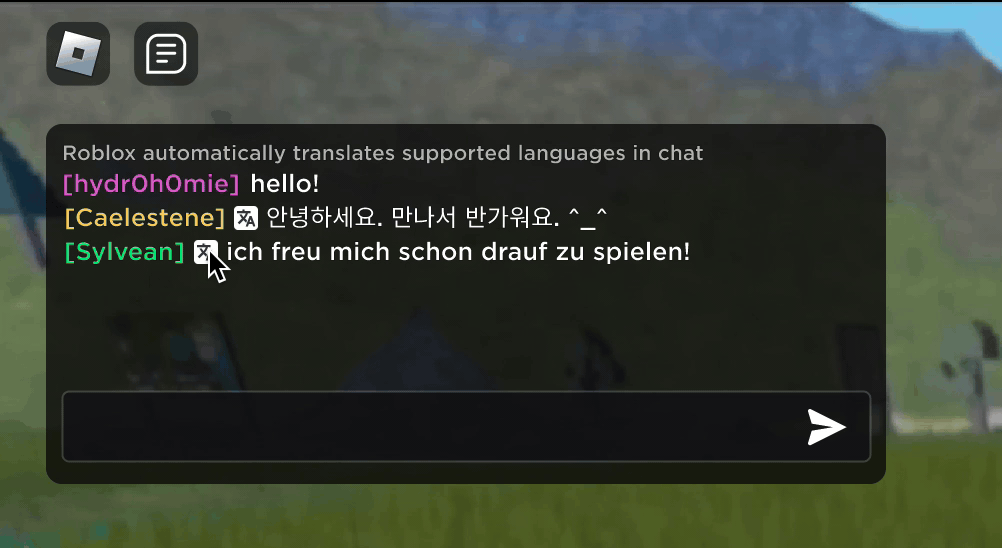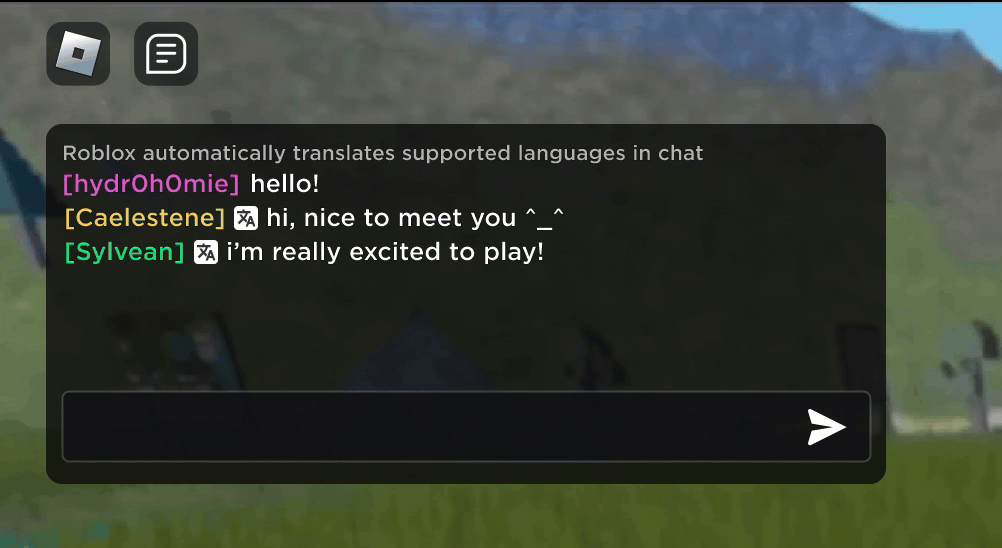
Stell dir vor, du entdeckst, dass deine neue Roblox-Bekanntschaft, mit der du in einem neuen Erlebnis gechattet und Witze gemacht hast, tatsächlich in Korea wohnt und die ganze Zeit auf Koreanisch geschrieben hat, während du die ganze Zeit auf Deutsch getippt hast, ohne dass es einer von euch bemerkt hat. Dank unserer neuen KI-Chat-Übersetzungen in Echtzeit haben wir auf Roblox etwas ermöglicht, das es nicht einmal in der physischen Welt gibt – Menschen, die verschiedene Sprachen sprechen, können in unseren immersiven 3D-Erlebnissen nahtlos miteinander kommunizieren. Dies ist dank unseres eigens erstellten multilingualen Sprachmodells möglich, das jetzt eine direkte Übersetzung zwischen jeder Kombination der 16 Sprachen ermöglicht, die wir derzeit unterstützen (diese 15 Sprachen sowie Englisch).
In jedem Erlebnis, in dem unser erlebnisinterner Textchat-Dienst aktiviert ist, können Menschen aus unterschiedlichen Ländern jetzt von Leuten verstanden werden, die ihre Sprache nicht sprechen. Das Chatfenster zeigt automatisch Übersetzungen von Koreanisch ins Deutsche oder von Türkisch ins Englische an, und umgekehrt, sodass alle Gesprächspartner:innen den Chat in ihrer eigenen Sprache lesen können. Diese Übersetzungen werden in Echtzeit angezeigt, mit einer Latenz von ca. 100 Millisekunden oder weniger, sodass der Übersetzungsprozess, der im Hintergrund läuft, nahezu unsichtbar ist. Die Verwendung von KI zur Automatisierung von Echtzeitübersetzungen im Textchat beseitigt Sprachbarrieren und bringt mehr Menschen zusammen, unabhängig davon, in welchem Land sie leben.
Die Entwicklung eines vereinheitlichten Übersetzungsmodells
Die KI-Übersetzung ist natürlich nichts Neues; ein Großteil unserer Erlebnisinhalte wird bereits automatisch übersetzt. Wir wollten jedoch über die Übersetzung statischer Inhalte in Erlebnissen hinausgehen. Unser Ziel war es, Interaktionen automatisch in alle 16 Sprachen zu übersetzen, die wir auf der Plattform unterstützen. Dies war in zweierlei Hinsicht ehrgeizig: Erstens übersetzen wir nicht nur von einer primären Sprache (d. h. Englisch) in eine andere, sondern wollten ein System, das Übersetzungen in allen Kombinationen der von uns unterstützten 16 Sprachen ermöglicht. Zweitens musste die Übersetzung schnell genug sein, um reale Chat-Gespräche zu unterstützen. Für uns bedeutete das, die Latenz auf ca. 100 Millisekunden oder weniger zu reduzieren.
Auf Roblox sind mehr als 70 Millionen täglich aktive Nutzer:innen aus der ganzen Welt unterwegs, und diese Zahl wächst stetig. Sie kommunizieren und kreieren auf unserer Plattform rund um die Uhr jeweils in ihrer Muttersprache. Jedes Gespräch in mehr als 15 Millionen aktiven Erlebnissen manuell und in Echtzeit zu übersetzen, ist offensichtlich nicht machbar. Das Skalieren dieser Live-Übersetzungen für Millionen von Menschen, die alle gleichzeitig in verschiedenen Erlebnissen unterschiedliche Gespräche führen, erfordert ein LLM mit enormer Geschwindigkeit und Genauigkeit. Wir benötigen ein kontextsensitives Modell, das Roblox-spezifische Sprache erkennt, einschließlich Slang und Abkürzungen (z. B. „Obby“, „afk“ oder „lol“). Darüber hinaus muss unser Modell jede Kombination der 16 Sprachen unterstützen, die Roblox derzeit unterstützt.
Um dieses Ziel zu erreichen, hätten wir für jedes Sprachpaar (z. B. Japanisch und Spanisch) ein einzigartiges Modell entwickeln können, was jedoch 16×16, also 256 verschiedene Modelle, erfordert hätte. Stattdessen haben wir ein vereinheitlichtes, auf Transformer basierendes Übersetzungs-LLM aufgebaut, um alle Sprachenpaare in einem einzigen Modell zu bedienen. Dies ist vergleichbar mit einem Team von Übersetzungsexperten, von denen jeder auf eine Gruppe ähnlicher Sprachen spezialisiert ist. Jetzt genügt ein Ausgangssatz und eine Zielsprache, um den entsprechenden „Experten“ zu aktivieren und die Übersetzungen zu generieren.
Diese Architektur ermöglicht eine effektivere Nutzung von Ressourcen, da jeder Experte ein unterschiedliches Spezialgebiet hat, was zu effizienterem Training und Inferenz führt, ohne die Übersetzungsqualität zu beeinträchtigen.
Darstellung des Inferenzprozesses. Ausgangsnachrichten zusammen mit der Ausgangs- und Zielsprache werden durch RCC übermittelt. Bevor sie das Backend erreichen, überprüfen wir zunächst den Cache, um zu sehen, ob wir bereits Übersetzungen für diese Anfrage haben. Falls nicht, wird die Anfrage an das Backend und den Modellserver mit dynamischer Stapelverarbeitung weitergeleitet. Wir haben eine Einbettungs-Cache-Ebene zwischen den Encodern und Decodern hinzugefügt, um die Effizienz beim Übersetzen in mehrere Zielsprachen weiter zu verbessern.
Diese Architektur macht es aus mehreren Gründen wesentlich effizienter, unser Modell zu trainieren und zu pflegen. Erstens kann unser Modell linguistische Ähnlichkeiten zwischen Sprachen nutzen. Wenn alle Sprachen gemeinsam trainiert werden, profitieren ähnliche Sprachen wie Spanisch und Portugiesisch voneinander während des Trainings, was die Übersetzungsqualität für beide Sprachen verbessert. Wir können auch wesentlich einfacher neue Forschungsergebnisse und Fortschritte in LLMs testen und in unser System integrieren, sobald sie verfügbar sind, um von den neuesten verfügbaren Techniken zu profitieren. Einen weiteren Vorteil dieses vereinheitlichten Modells sehen wir in Fällen, in denen die Ausgangssprache nicht festgelegt oder falsch festgelegt ist. Das Modell ist genau genug, um die korrekte Ausgangssprache zu erkennen und in die Zielsprache zu übersetzen. Tatsächlich kann das System selbst dann, wenn die Eingabe aus verschiedenen Sprachen besteht, die Zielsprache erkennen und übersetzen. In diesen Fällen ist die Genauigkeit möglicherweise nicht ganz so hoch, aber die übersetzte Nachricht wird gut verständlich sein.
Um dieses vereinheitlichte Modell zu trainieren, begannen wir mit dem Pretraining an verfügbaren Open-Source-Daten sowie an unseren eigenen erlebnisinternen Übersetzungsdaten, von Menschen gelabelten Chat-Übersetzungsergebnissen und gängigen Chat-Sätzen und -Phrasen. Außerdem haben wir unsere eigene Übersetzungsbewertungsmetrik und ein Modell entwickelt, um die Übersetzungsqualität zu messen. Die meisten Standard-Übersetzungsqualitätsmetriken vergleichen das KI-Übersetzungsergebnis mit einer Referenzübersetzung und konzentrieren sich hauptsächlich auf die Verständlichkeit der Übersetzung. Wir wollten jedoch die Qualität der Übersetzung bewerten, und zwar ohne eine Referenzübersetzung.
Wir betrachten dies aus mehreren Aspekten, einschließlich Genauigkeit (ob es irgendwelche Hinzufügungen, Auslassungen oder Fehlübersetzungen gibt), Flüssigkeit (Interpunktion, Rechtschreibung und Grammatik) und falsche Verweise (Diskrepanzen mit dem restlichen Text). Diese Fehler klassifizieren wir in Schweregrade: Handelt es sich um einen kritischen, einen wichtigen oder einen geringfügigen Fehler? Um die Qualität zu bewerten, haben wir ein ML-Modell entwickelt und es auf menschlich gelabelte Fehlerarten und Punktzahlen trainiert. Anschließend haben wir an unserem mehrsprachigen Sprachmodell gefeilt, um Fehler und Fehlerarten auf Wortebene vorherzusagen und anhand unserer multidimensionalen Kriterien eine Punktzahl zu berechnen. Dies gibt uns ein umfassendes Verständnis über die Qualität und die Arten von Fehlern, die auftreten. Auf diese Weise können wir ohne die Notwendigkeit einer Referenzübersetzung die Übersetzungsqualität einschätzen und Fehler erkennen, indem wir Ausgangstext und Maschinenübersetzungen verwenden. Mit den Ergebnissen dieses Qualitätsmaßes können wir die Qualität unseres Übersetzungsmodells weiter verbessern.
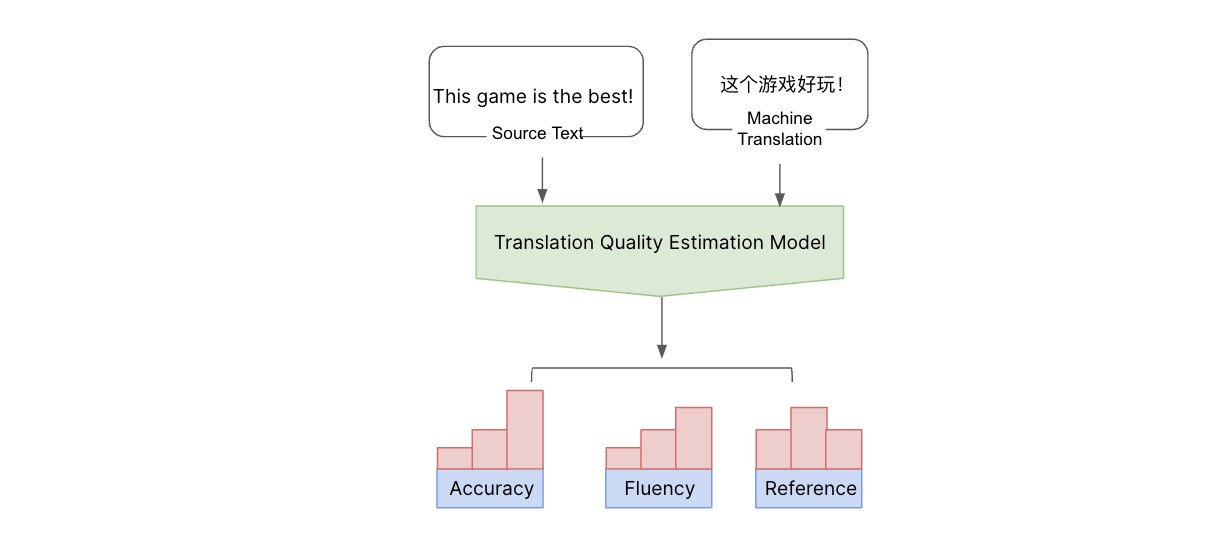
Mit dem Ausgangstext und dem maschinellen Übersetzungsergebnis können wir mithilfe unseres hausinternen Qualitätsschätzmodells für Übersetzungen die Qualität der maschinellen Übersetzung ohne Referenzübersetzung einschätzen. Dieses Modell beurteilt die Qualität anhand verschiedener Aspekte und kategorisiert Fehler in kritische, wichtige und geringfügige Fehler.
Seltenere Übersetzungspaare (zum Beispiel vom Französischen ins Thailändische) sind aufgrund des Mangels an hochwertigen Daten eine Herausforderung. Um diese Lücke zu füllen, haben wir Rückübersetzungen angewendet, bei denen Inhalte zurück in die Ausgangssprache übersetzt werden und dann mit dem Ausgangstext auf Genauigkeit verglichen werden. Während des Trainingsvorhangs haben wir iterative Rückübersetzungen verwendet, bei denen wir eine strategische Mischung aus diesen rückübersetzten Daten und überwachten (gelabelten) Daten einsetzen, um die Menge der Übersetzungsdaten für das Modell zum Lernen zu erweitern.
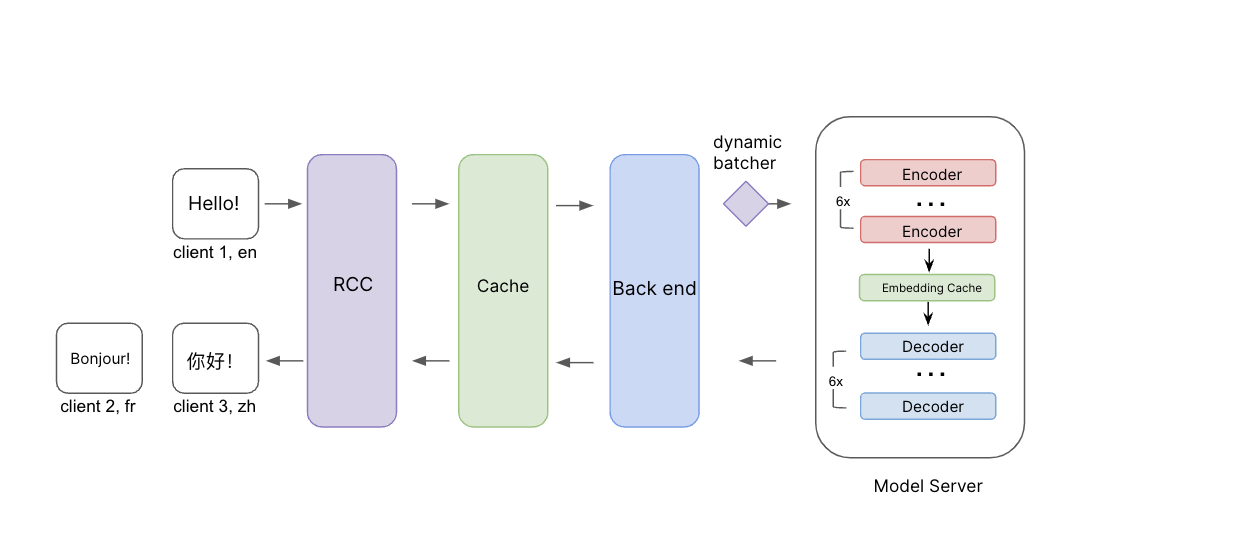
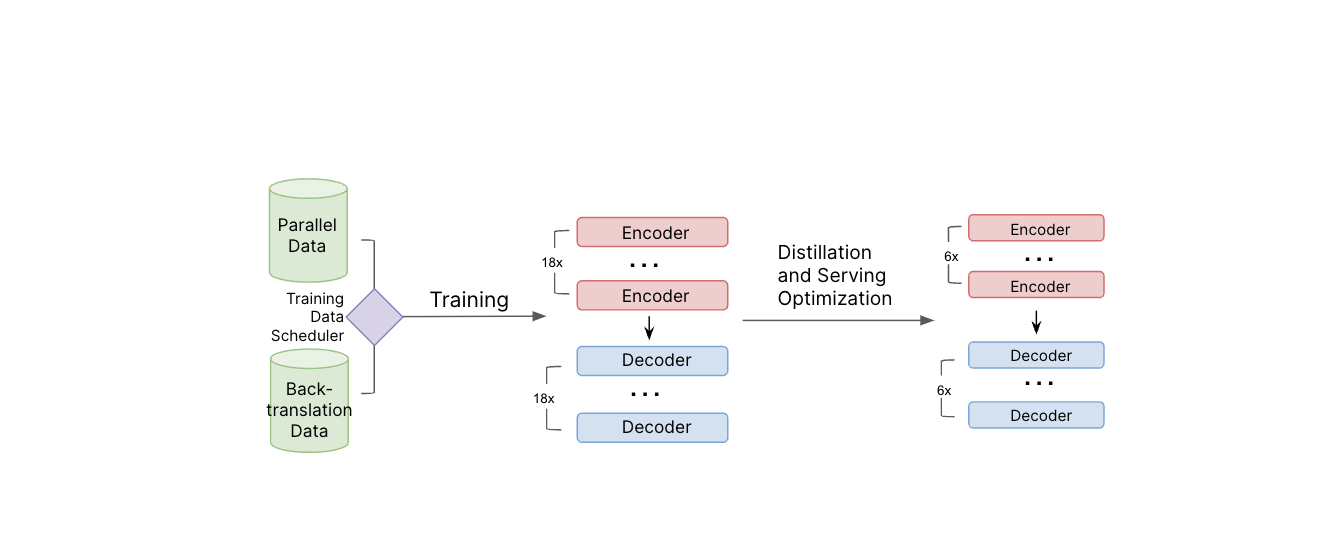
Illustration der Modell-Trainingspipeline. Sowohl parallele Daten als auch Rückübersetzungsdaten werden während des Modelltrainings verwendet. Nachdem das Lehrmodell trainiert ist, wenden wir Destillation und andere Techniken zur Optimierung der Bereitstellung an, um die Modellgröße zu reduzieren und die Bereitstellungseffizienz zu verbessern.
Um dem Modell zu helfen, moderne Umgangssprache zu verstehen, haben wir menschliche Evaluator:innen gebeten, populäre und trendige Begriffe für jede Sprache zu übersetzen und haben diese Übersetzungen in unsere Trainingsdaten aufgenommen. Wir werden diesen Vorgang regelmäßig wiederholen, um das System auf dem neuesten Stand der aktuellen Umgangssprache zu halten.
Das resultierende Chat-Übersetzungsmodell hat ungefähr 1 Milliarde Parameter. Die Ausführung einer Übersetzung durch ein so großes Modell ist aufgrund des enormen Ressourcenbedarfs beim Skalieren nicht durchführbar und würde viel zu lange für ein Echtzeitgespräch dauern, bei dem eine geringe Latenz entscheidend ist, um mehr als 5.000 Chats pro Sekunde zu unterstützen. Daher haben wir dieses große Übersetzungsmodell in einem Lehrer-Schüler-Ansatz verwendet, um ein kleineres, leichteres Modell zu erstellen. Wir haben Destillation, Quantisierung, Modellkompilierung und andere Bereitstellungsoptimierungen angewendet, um die Größe des Modells auf weniger als 650 Millionen Parameter zu reduzieren und die Bereitstellungseffizienz zu verbessern. Darüber hinaus haben wir die API hinter dem erlebnisinternen Textchat so modifiziert, dass sowohl die originalen als auch die übersetzten Nachrichten an das Gerät der Person gesendet werden. Dies ermöglicht es den Empfänger:innen, die Nachricht in ihrer Muttersprache zu sehen oder schnell zu der ursprünglichen, nicht übersetzten Nachricht der Absender:in zu wechseln.
Sobald das endgültige LLM bereit war, haben wir ein Backend implementiert, um eine Verbindung mit den Modellservern herzustellen. In diesem Backend wenden wir zusätzliche Chat-Übersetzungslogik an und integrieren das System mit unseren üblichen Sicherheitssystemen. Dies gewährleistet, dass übersetzter Text die gleichen Überprüfung unterliegt wie anderer Text, um Wörter oder Ausdrücke zu erkennen und zu blockieren, die gegen unsere Richtlinien verstoßen. Sicherheit und Anstand stehen bei allem, was wir bei Roblox tun, an erster Stelle, daher war dies ein sehr wichtiger Teil des Puzzles.
Kontinuierliche Verbesserung der Genauigkeit
Bei unseren Tests haben wir festgestellt, dass dieses neue Übersetzungssystem zu einer stärkeren Beteiligung und einer höheren Sitzungsqualität für die Personen auf unserer Plattform führt. Basierend auf unserer eigenen Metrik übertrifft unser Modell kommerzielle Übersetzungs-APIs für Roblox-Inhalte, was darauf hindeutet, dass wir unser Modell erfolgreich auf den Kommunikationsstil auf Roblox optimiert haben. Wir sind gespannt darauf zu sehen, wie dies die Erfahrung für die Menschen auf der Plattform verbessert und es ihnen ermöglicht, Spiele zu spielen, einzukaufen, zusammenzuarbeiten oder sich einfach mit Freund:innen auszutauschen, die eine andere Sprache sprechen.
Die Möglichkeit für Menschen, nahtlose, natürliche Gespräche in ihrer Muttersprache zu führen, bringt uns unserem Ziel näher, eine Milliarde Menschen mit Optimismus und Anstand zu verbinden.
Um die Genauigkeit unserer Übersetzungen weiter zu verbessern und unserem Modell bessere Trainingsdaten zur Verfügung zu stellen, planen wir, ein Tool einzuführen, das es den Personen auf der Plattform ermöglicht, Feedback über ihre Übersetzungen abzugeben und dem System zu helfen, sich noch schneller zu verbessern. Somit können Nutzer:innen sich bei uns melden, wenn sie eine fehlerhafte Übersetzung sehen, und sogar einen besseren Übersetzungsvorschlag unterbreiten, den wir in die Trainingsdaten aufnehmen können, um das Modell weiter zu verbessern.
Diese Übersetzungen sind heute für alle 16 von uns unterstützten Sprachen verfügbar – aber wir sind noch lange nicht fertig. Wir planen, unsere Modelle weiterhin mit den neuesten Übersetzungsbeispielen aus unseren Erlebnissen sowie mit populären Chat-Phrasen und den neuesten Slang-Phrasen in jeder von uns unterstützten Sprache zu aktualisieren. Darüber hinaus wird diese Architektur es ermöglichen, das Modell mit vergleichsweise geringem Aufwand auf neue Sprachen zu trainieren, sobald ausreichende Trainingsdaten für diese Sprachen verfügbar sind. Zudem erkunden wir Möglichkeiten, automatische Übersetzungen bei anderen Dimensionen anzuwenden: Text auf Bildern, Texturen, 3D-Modellen usw.
Und wir erkunden bereits spannende neue Möglichkeiten, einschließlich automatischer Voice-Chat-Übersetzungen. Stell dir vor, eine Französisch sprechende Benutzer:in auf Roblox könnte mit jemandem sprechen, der nur Russisch spricht. Beide könnten miteinander sprechen und einander verstehen und sogar Ton, Rhythmus und die Emotion ihrer Stimme in ihrer eigenen Sprache bei geringer Latenz vermitteln. Auch wenn dies heute noch wie Science-Fiction klingen mag und es einige Zeit dauern wird, bis wir dieses Ziel erreichen, werden wir weiterhin an Übersetzungen arbeiten. n naher Zukunft wird Roblox ein Ort sein, an dem Menschen aus der ganzen Welt nahtlos und mühelos nicht nur über Textchat, sondern in jeder möglichen Modalität kommunizieren können!