Quebrando barreiras de idioma com um modelo de tradução multilíngue
by Daniel Sturman, Chief Technology Officer
Tecnologia
Imagine descobrir que sua nova amizade na Roblox, uma pessoa com você tem feitos piadas e conversado em nova experiência, está na Coréia – e que esteve digitando coreano o tempo todo enquanto você estava digitando em português. E nenhum de vocês notou isso. Graças a nossa tradução em tempo real usando IA, tornamos possível na Roblox algo que nem é possível no mundo real: permitir que pessoas que falam diferentes línguas se comuniquem sem restrições em nossas experiências 3D imersivas. Isso é possível como nosso LLM (modelo grande de linguagem) multilíngue personalizado, que agora permite a tradução direta entre qualquer combinação dos idiomas que suportamos no momento (15 idiomas e o inglês).
Em qualquer experiência que tenha o nosso serviço de conversa por texto na experiência ativado, pessoas de diferentes países agora podem ser entendidas por pessoas que não falam seu idioma. A janela de chat vai mostrar automaticamente coreano traduzido para português ou turco traduzido para alemão – e vice-versa, assim, cada pessoa vê a conversa em seu próprio idioma. Essas traduções são mostradas em tempo real, com uma latência de aproximadamente 100 milissegundos ou menos, fazendo com que a tradução que ocorre nos bastidores seja praticamente invisível. Usando IA para automatizar traduções em tempo real na conversa por texto remove quaisquer barreiras de linguagem e aproxima mais as pessoas, não importa onde elas vivam no mundo.
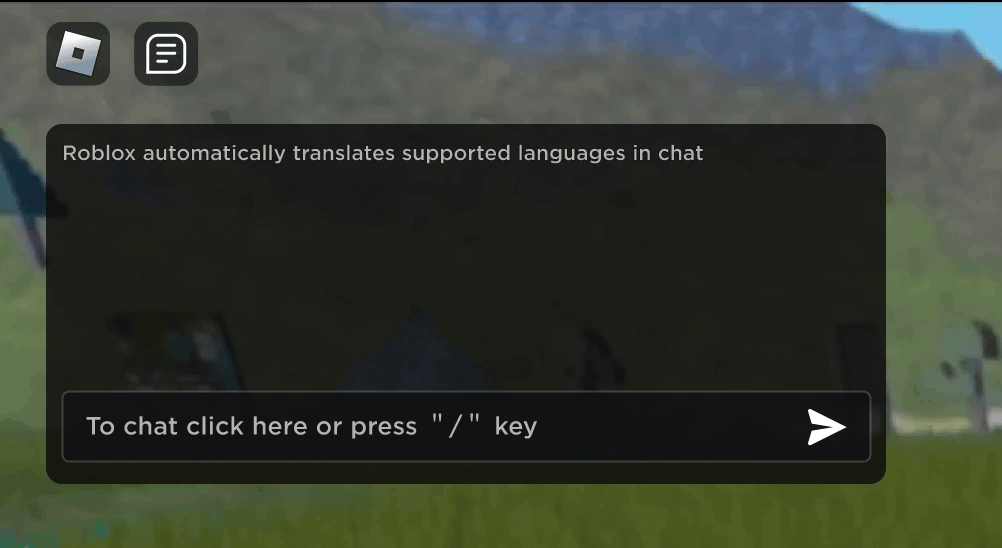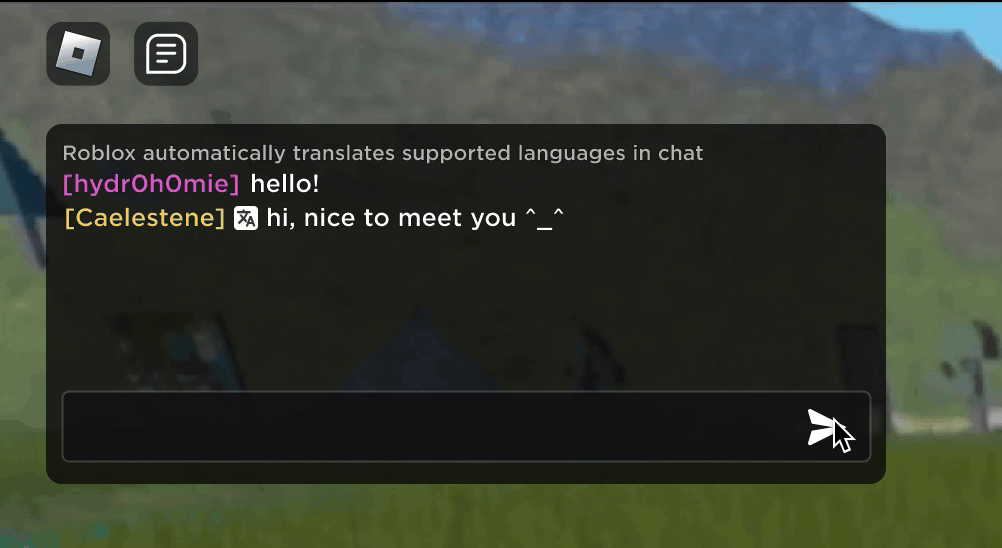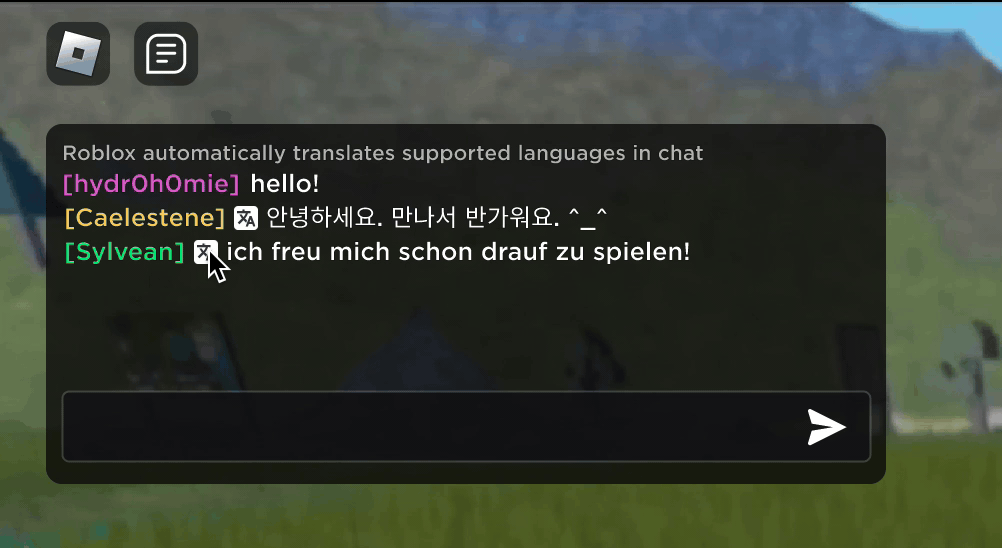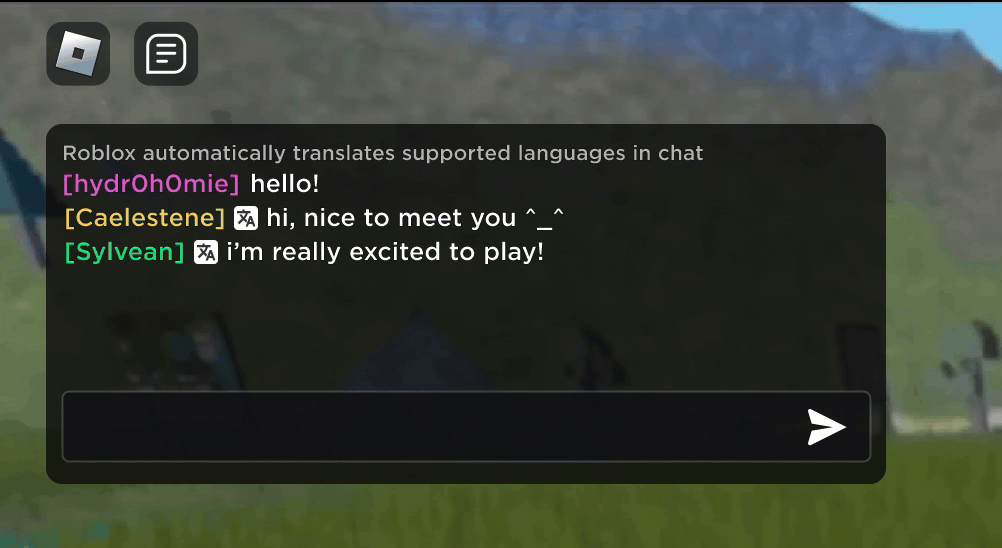
Construindo um modelo unificado de tradução
Traduções por IA não são nenhuma novidade, a maioria de nosso conteúdo em experiências já é traduzido automaticamente. Mas queríamos ir além da tradução de conteúdo estático nas experiências. Queremos interação com tradução automática – e queremos isso para os 16 idiomas que suportamos na plataforma. Esse foi um objetivo audacioso por dois motivos: Primeiro, não queríamos só traduzir de uma linguagem primária (como o inglês) para outra, queríamos um sistema capaz de traduzir entre qualquer combinação dos 16 idiomas que suportamos. Segundo, tinha que ser rápido. Rápido o bastante para suportar conversas reais, o que significava para nós ter uma latência de aproximadamente 100 milissegundos ou menos.
A Roblox é o lar de mais de 70 milhões de usuários ativos diários em todo mundo, com esse número aumentando continuamente. As pessoas se comunicam e criam em nossa plataforma – cada uma delas em seu idioma nativo – 24 horas por dia. Traduzir manualmente cada conversa que acontece em mais de 15 milhões de experiências em tempo real é obviamente impossível. Escalar essas traduções ao vivo para milhões de pessoas, todas tendo diferentes conversas em diferentes experiências ao mesmo tempo, requer um LLM com velocidade e precisão tremendas. Precisamos de um modelo que observe contexto e que reconheça linguagem específica da Roblox, incluindo gírias e abreviações (como obby, afk, lol). Além disso tudo, nosso modelo precisa suportar qualquer combinação dos 16 idiomas que a Roblox suporta no momento.
Para conseguir isso, poderíamos ter construído um modelo único para cada par de idiomas (por exemplo, japonês e espanhol), mas isso iria precisar de 16×16 modelos, ou seja, 256 modelos. Em vez disso, construímos um LLM unificado com tradução baseada em transformações e aplicamos uma arquitetura com mistura de expertises. Isso é o equivalente a ter vários aplicativos de tradução, cada um especializado em um grupo de idiomas similares, todos disponíveis em uma única interface. Dada uma sentença original e uma linguagem alvo, podemos ativar o “expert” relevante para gerar as traduções.
Esta arquitetura permite um melhor uso de recursos, já que cada expert tem uma especialidade diferente que leva a um treinamento e inferência mais eficientes sem sacrificar a qualidade de tradução.
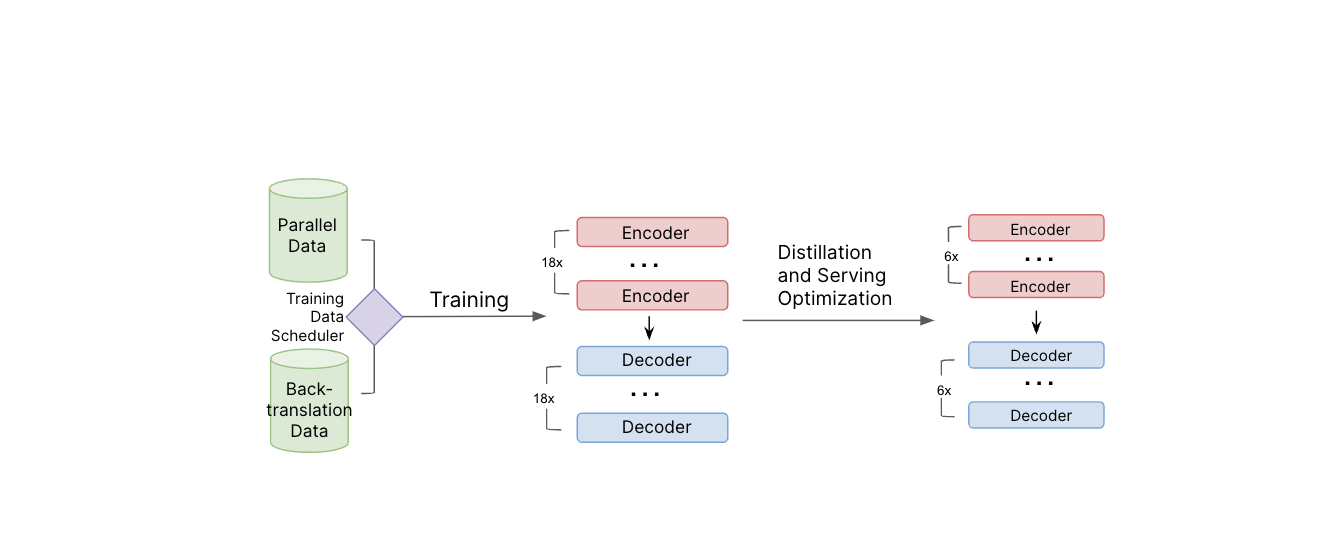
Ilustração do processo de inferência. Mensagens da origem, bem como idioma de origem e idioma alvo são passados através da Nuvem de Computação da Roblox (Roblox Compute Cloud – RCC). Antes de chegar no back end, primeiro checamos o cache para ver se já temos tradução para essa solicitação. Se não, a solicitação é passada para o back end e para o servidor modelo com agrupamento dinâmico. Adicionamos uma camada de integração de cache entre os codificadores e decodificadores para melhorar ainda mais a eficiência quando traduzimos em vários idiomas alvo.
Esta arquitetura torna mais fácil e eficiente para treinar e manter nosso modelo por algumas razões. Primeiro, nosso modelo é capaz de alavancar similaridades linguísticas entre idiomas. Quando todos os idiomas são treinados juntos, idiomas que são parecidos, como espanhol e português, se beneficiam um do outro durante o treino – o que ajuda a melhorar a qualidade de tradução para ambos os idiomas. Também podemos treinar e integrar novas pesquisas e avanços em LLMs muito mais facilmente em nosso sistema à medida em que esses avanços são lançados, para beneficiar a todos com as melhores e mais recentes técnicas disponíveis. Outro benefício que vemos neste modelo unificado em casos em que o idioma de origem não é definido ou é definido incorretamente, quando o modelo é preciso o suficiente para detectar o idioma de origem correto e traduzi-lo para o idioma alvo. De fato, até mesmo se a entrada tiver uma mistura de idiomas, o sistema ainda é capaz de detectar e traduzir no idioma alvo. Nesses casos, a precisão pode ser tão alta, mas a mensagem final poderá ser entendida.
Para treinar este modelo unificado, começamos pré-treinando em bases de dados de código aberto disponíveis, bem como em nossos próprios dados de tradução em experiências, resultados de tradução de conversas marcadas por humanos e frases comuns de conversas de texto. Também construímos nossa própria métrica de avaliação e um modelo para medir a qualidade de tradução. A maioria das métricas de tradução disponíveis comercialmente comparam o resultado da tradução de IA com dados reais ou traduções de referência e se concentram primariamente no entendimento da tradução. Queríamos avaliar a qualidade da tradução, mas sem uma tradução real de referência.
Olhamos isso de vários aspectos, incluindo precisão (incluindo casos com adições, omissões e traduções incorretas), fluência (pontuação, ortografia e gramática) e referências incorretas (discrepâncias com o resto do texto). Classificamos esses erros em níveis de severidade: O erro é maior, menor ou crítico? Para avaliar a qualidade, construímos um modelo de aprendizado de máquina e o treinamos em tipos de erros e pontuações marcados por humanos. Em seguida, melhoramos um modelo multilíngue para predizer erros ao nível de palavra e tipos, calculando uma pontuação usando nosso critério multidimensional. Isso nos dá um entendimento abrangente da qualidade e dos tipos de erros ocorrendo. Dessa maneira, podemos estimar a qualidade das traduções e detectar erros usando texto de origem e traduções de máquina sem precisar de traduções de referência. Usando os resultados dessa medida de qualidade, podemos melhorar ainda mais a qualidade de nosso modelo de tradução.
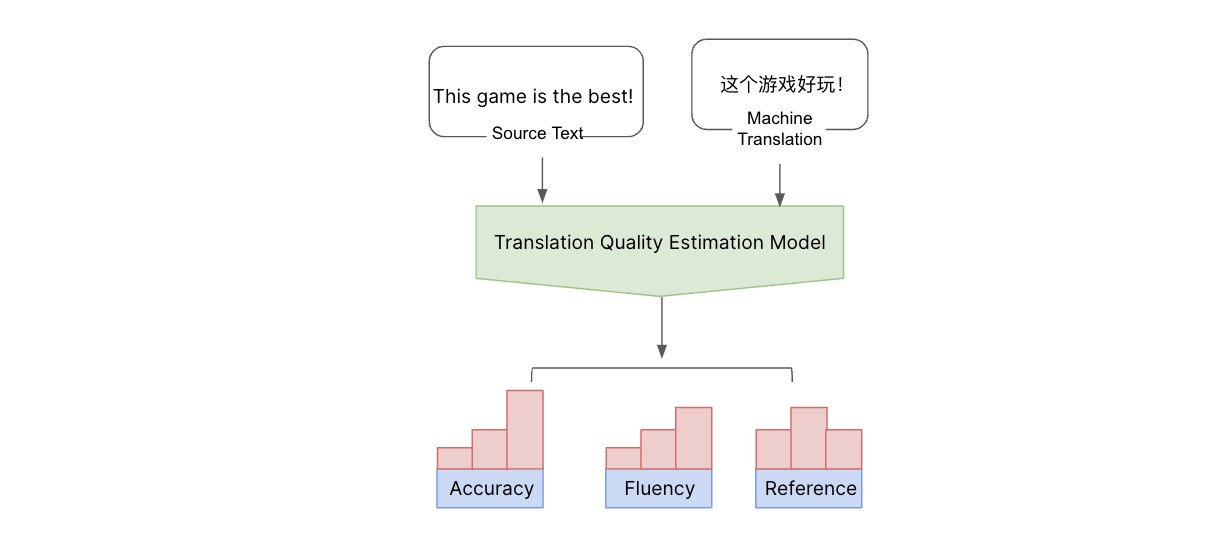
Com o texto de origem e o resultado da tradução de máquina, podemos estimar a qualidade da tradução de máquina sem uma tradução de referência, usando nosso modelo de estimativa de qualidade de tradução. Esse modelo estima a qualidade a partir de diferentes aspectos e os categoriza entre crítico, maior e menor.
Pares de tradução menos comuns (por exemplo, tailandês e francês) são desafiadores devido à falta de dados de alta qualidade. Para preencher essa lacuna, aplicamos tradução reversa, onde o conteúdo é traduzido de volta no idioma original e depois é comparado com o texto original para verificar a precisão. Durante o processo de treinamento, usamos tradução reversa iterativa, onde usamos uma mistura estratégica de dados de tradução reversa e supervisionada (marcada por humanos) para expandir a quantidade de dados de tradução para modelo aprender.
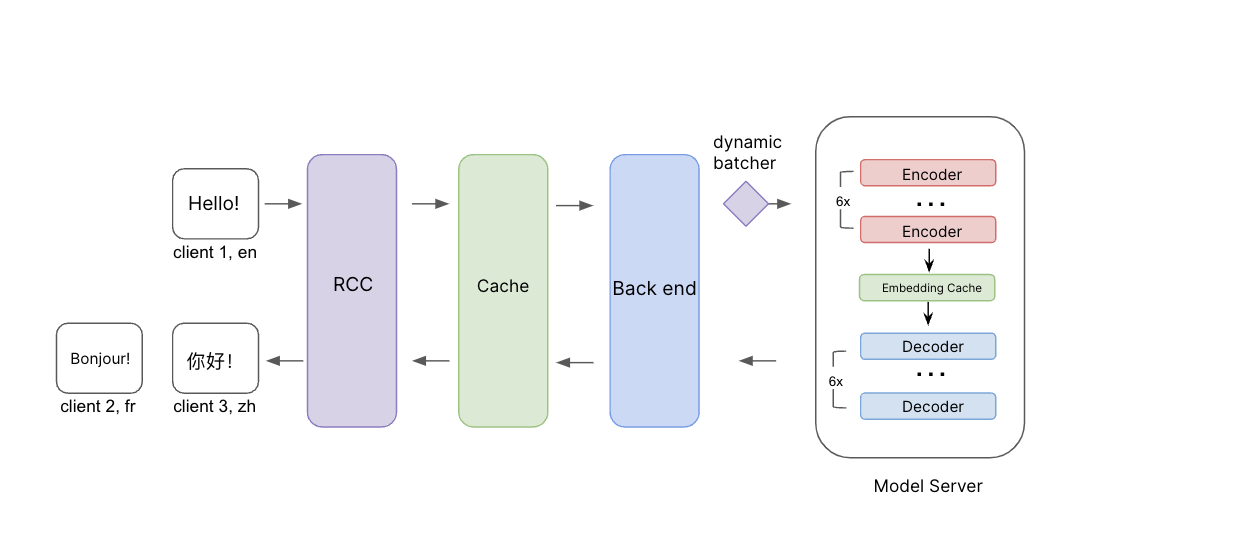
Ilustração do sistema de treinamento do modelo. Dados paralelos e de tradução reversa são usados durante o treinamento do modelo. Depois que o modelo professor é treinado, aplicamos destilação e outras técnicas de otimização de serviço para reduzir o tamanho do modelo e melhorar a eficiência de serviço.
Para ajudar o modelo a entender gírias modernas, pedimos que avaliadores humanos traduzissem termos populares e em voga e incluímos essas traduções em nossos dados de treinamento. Continuaremos a repetir este processo regularmente para manter o sistema atualizado com as gírias mais recentes.
O modelo resultante de tradução de conversas de texto tem aproximadamente um bilhão de parâmetros. Executar uma tradução através de um modelo desse tamanho proibitivo em termos de intensidade de recursos para servir em escala e levaria tempo demais para uma conversa em tempo real, onde a lat6encia é crítica para suportar mais de cinco mil conversas por segundo. Então usamos este grande modelo de linguagem de um modo “estudante-professor” para construir uma modelo menor e menos pesado. Aplicamos destilação, quantização, compilação de modelo e outras otimizações de serviço para reduzir o tamanho do modelo para menos de 650 milhões de parâmetros e melhorar a eficiência de serviço. Além disso, modificamos a API por trás das conversas de texto em experiência para mandar ambas as mensagens originais e traduzidas para o dispositivo da pessoa. Isso permite que o recipiente veja a mensagem em sua linguagem nativa ou mude rapidamente para ver a mensagem original do remetente em sua forma não traduzida.
Quando o LLM final estava pronto, implementamos um back end para conectar com outros servidores de modelos. Esse back end é onde aplicamos lógicas adicionais de tradução de chat e integramos o sistema com nossos sistemas de segurança e confiabilidade usuais. Isso garante que textos traduzidos passem mesmo nível de monitoramento de outros textos e que sejam detectadas palavras e frases que violem nossas políticas. Segurança e civilidade são a prioridade maior em tudo que fazemos na Roblox e essa era uma peça importante do quebra-cabeça.
Melhorando a precisão continuamente
Em testes, vimos esse novo sistema de tradução guia um engajamento e qualidade de sessões maiores para as pessoas em nossa plataforma. Com base em nossas próprias métricas, nosso modelo supera APIs de tradução comerciais em conteúdo Roblox, indicando que otimizamos com sucesso a forma como as pessoas se comunicam na plataforma. Estamos animados para ver como isso vai melhorar a experiência de uso da plataforma para as pessoas, fazendo possível que elas joguem jogos, façam compras, colaborem ou simplesmente conversem com amigos que falam um idioma diferente.
A habilidade de ter conversas ininterruptas e naturais em seus idiomas nativos nos aproxima de nosso objetivo de conectar um bilhão de pessoas com otimismo e civilidade.
Para melhorar ainda mais a precisão de nossas traduções e fornecer nosso modelo com dados de treinamento melhores, planejamos distribuir uma ferramenta que permite que as pessoas na plataforma deem feedback para as traduções e ajudem o sistema a melhorar mais rápido. Isso iria permitir que uma pessoa nos dissesse se ela viu algo que foi mal traduzido e até mesmo sugerir uma tradução melhor que podemos adicionar aos dados de treinamento para melhorar o modelo.
Essas traduções estão disponíveis hoje para os 16 idiomas que suportamos, mas não estamos nem perto de terminar. Planejamos continuar atualizando nossos modelos com os exemplos de tradução mais recentes diretamente de nossas experiências, bem como incluir expressões populares e gírias modernas em todos os idiomas suportados. Além disso, essa arquitetura tornará possível treinar o modelo em novos idiomas com um esforço relativamente baixo, à medida que dados de treinamento suficientes sejam disponibilizados para esses idiomas. Além disso, estamos explorando maneiras de traduzir automaticamente tudo em múltiplas dimensões: textos em imagens, texturas, modelos 3D etc.
E estamos prontos para explorar novas fronteiras, incluindo tradução automática de conversa por voz. Imagine um falante de francês na Roblox, capaz de conversar por voz com alguém que só sabe falar russo. Ambos poderiam falar e se entender, até mesmo o tom de voz, ritmo e emoção na voz em seus próprios idiomas e com baixa latência. Pode até parecer ficção científica e vai levar algum tempo para alcançarmos isso, mas vamos continuar avançando nas traduções. Em um futuro não muito distante, a Roblox será um lugar onde pessoas de todo o mundo poderão se comunicar sem esforço não somente em conversas de texto, mas em todas as modalidades possíveis!