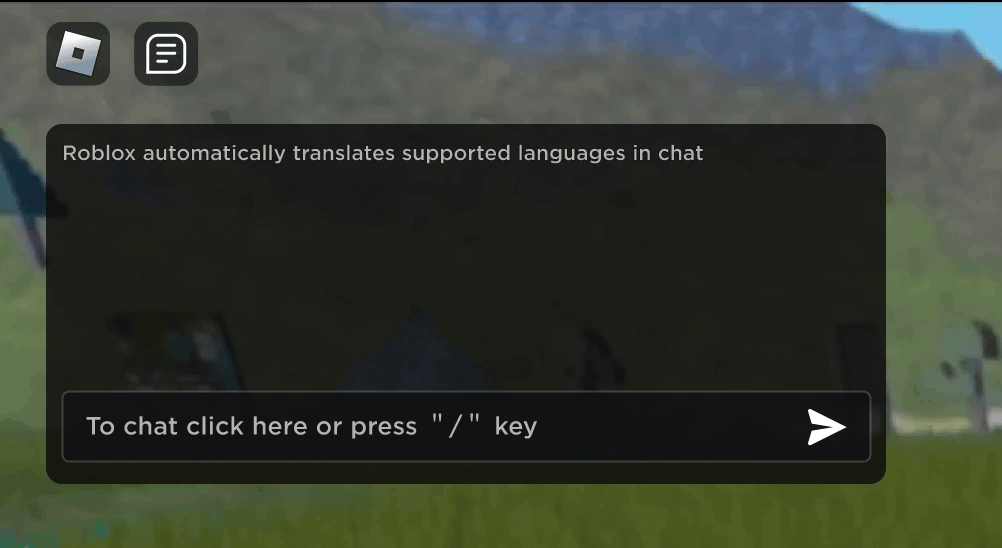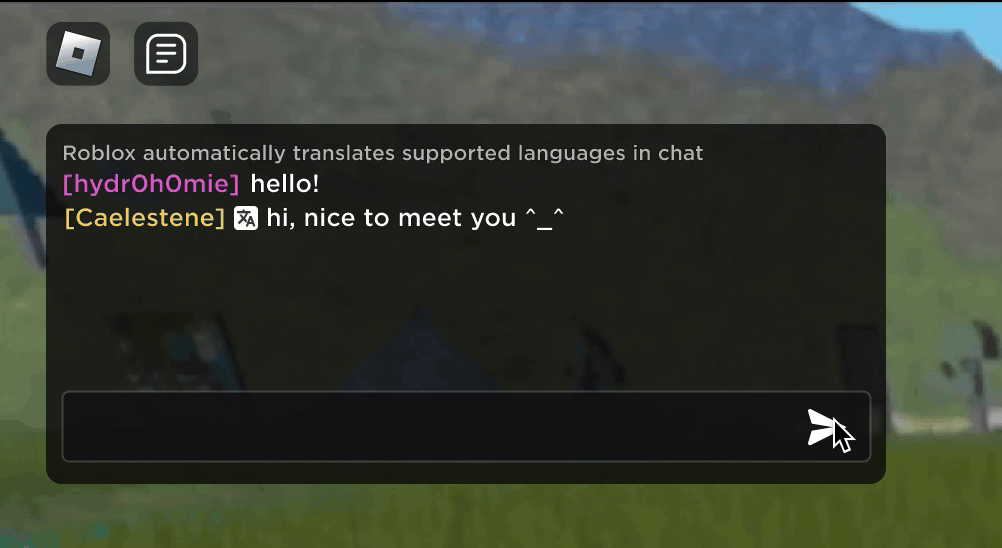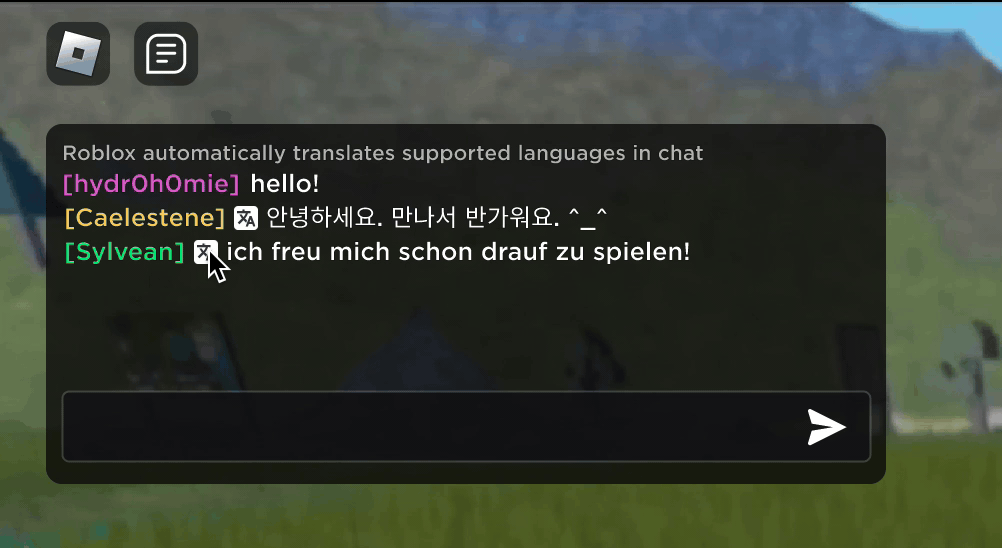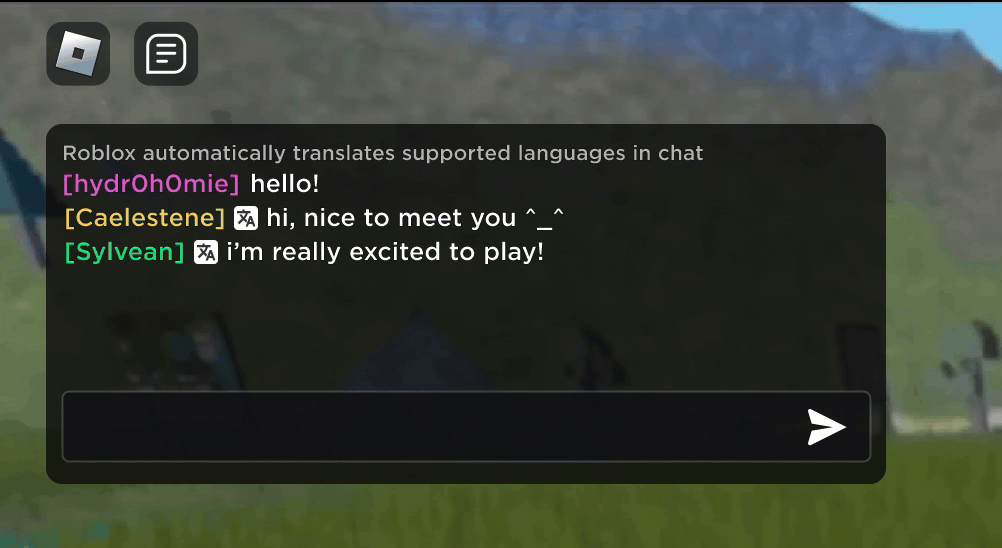
Roblox(ロブロックス)にある新しいバーチャル空間の中で英語で入力してチャットしたり冗談を言い合ったりしている新しい友達が、実は韓国にいて韓国語で入力していたと知ったときの驚きをイメージしてみてください。 新しいリアルタイムでのAI(人工知能)搭載チャット翻訳機能のおかげでRobloxではリアルの世界でもできなかったことができるようになりました。Robloxの没入感たっぷりの3Dバーチャル空間の中では、違う言葉を使う人同士が途切れなくコミュニケーションできるようになっています。 これは、多言語でのカスタム大規模言語モデル(LLM)のおかげで実現したもので、現在対応中の16ヶ国語間のあらゆる組み合わせ(15ヶ国語と英語)で直接、翻訳できるようになりました。
どのバーチャル空間内でもバーチャル空間テキストチャット サービスが使用できるようになり、言葉が分からない海外の方々にも理解してもらえるようになっています。 例えば、チャット・ウィンドウには、韓国語を英語に翻訳したもの、トルコ語をドイツ語に翻訳したもの、ドイツ語をトルコ語に翻訳したものなどが自動的に表示されます。 このような翻訳は、約100ミリ秒以下の遅延時間でリアルタイムに表示されるため舞台裏で起こっている翻訳作業はほとんど目には見えません。 AIを使ってテキストチャットのリアルタイム翻訳を自動化することで、世界のどこに住んでいても言葉の壁を取り除いて大勢のみなさんを結びつけることができます。
統合翻訳モデルの構築
AIによる翻訳機能は目新しいものではなく、バーチャル空間内の大半はすでに自動翻訳されています。 当社ではバーチャル空間内の静的コンテンツの翻訳以上のことを成し遂げたいと考えました。 そこで当社は、みなさんのやりとりを自動的に翻訳しようと考えました。当社のプラットフォームで対応中の全16ヶ国語でこれをしようと考えたのです。 これは2つの理由から大掛かりな目標でした。まず、特定の主要言語(つまり英語)から別の言語への翻訳だけでなく、当社が対応中の16ヶ国語のうちのどの組み合わせでも翻訳できるシステムが欲しかったのです。 2つ目は、速くなければならないことです。実際のチャットの会話に対応するのに十分な速さ、つまり遅延時間を約100ミリ秒以下にしなければならないということです。
Robloxは世界中で7000万人以上のデイリーアクティブユーザーを抱え、その数は増え続けています。 当社のプラットフォームでは、みなさんは24時間、それぞれの母国語を使ってコミュニケーションしたり制作したりしています。 1,500万本以上ある稼働中のバーチャル空間で起きている会話をすべてリアルタイムで手動で翻訳することは、明らかに無理です。 このようなライブ翻訳を数百万人規模の方々に使っていただけるようにして全員が同時に違うバーチャル空間でそれぞれ会話を楽しんでいただくためには、驚異的なスピードと精度を持つ大規模言語モデルが必要になります。 スラングや略語(obby、afk、lolなど)を含むRobloxで使われている特有の表現を認識するコンテキスト対応モデルが必要になります。 さらに、Robloxが現在対応中の16ヶ国語の組み合わせにも翻訳モデルを対応させる必要があります。
これを実現するためには、それぞれの言語の組み合わせ(日本語とスペイン語など)ごとに独自のモデルを構築することもできたのですが、そうすると16X16で256種類のモデルが必要になります。 その代わり、すべての言語の組み合わせに一つのモデルで対応できる統一された変換器ベースの翻訳用大規模言語モデルを構築しました。 これは複数の翻訳アプリがついているようなもので、それぞれが似たような言語グループに特化していて、すべて単一のインターフェースで利用できるようになっています。 原文とターゲット言語があれば、関連する「エキスパート」を起動して翻訳を生成できます。
この構造は、各エキスパートに異なる専門性があるため、リソースを有効活用でき、翻訳のクオリティを犠牲にせずにさらに効率的な学習と推論を実現してくれます。
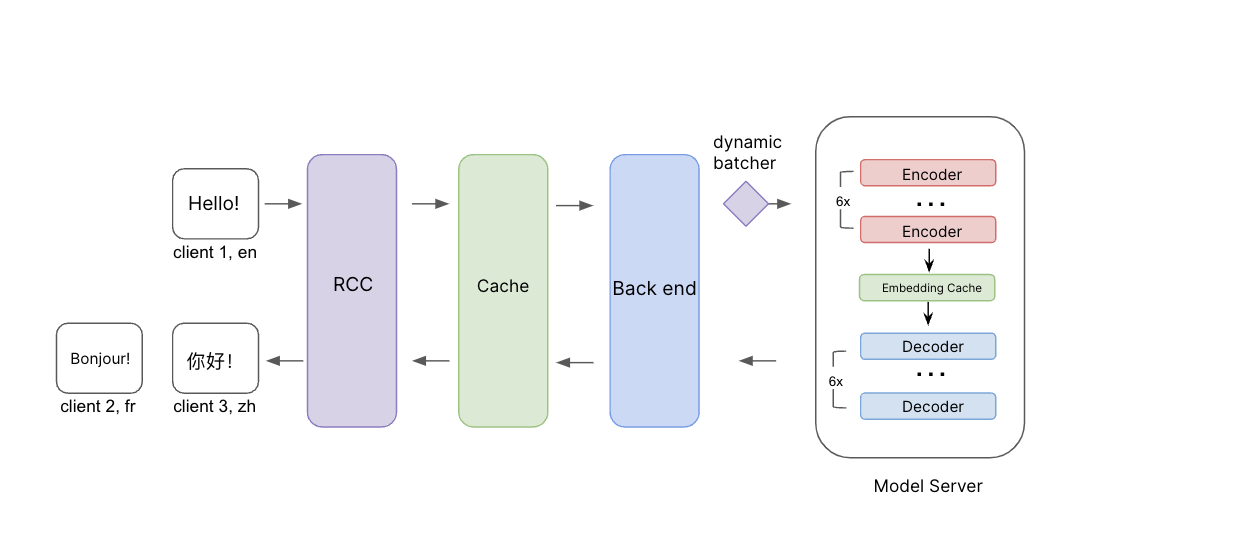
推論プロセスの図解。 ソース・メッセージは、ソース言語とターゲット言語とともにRCCに伝えられます。 バックエンドに行く前にまずキャッシュをチェックして、このリクエストに対する翻訳がすでにあるかどうかを確認します。 そうでない場合、リクエストはバックエンドに行き、動的バッチ処理でモデルサーバーに行きます。 エンコーダーとデコーダーの間に埋め込みキャッシュの層を追加して複数のターゲット言語に翻訳するときの効率をさらに向上させました。
この構造がモデルの訓練と維持ではるかに効率的なのにはいくつかの理由があります。 まず、当社のモデルは言語間の類似性を活用できるようになっています。 すべての言語が一緒に訓練されると、スペイン語とポルトガル語のように似ている言語は、訓練中にお互いの入力内容を使って両方の言語の翻訳品質を向上させるのに役立ちます。 また、大規模言語モデルの新しい研究や進歩が発表されるたびに、当社のシステムをテストしたり、新しい内容を組み込むことがはるかにやりやすくなり、利用可能で最新かつ最高のテクニックの恩恵を受けることができます。 この統合モデルのもう一つの利点は、ソース言語が設定されていないか間違って設定されている場合に表れます。このモデルは正しいソース言語を検出し、ターゲット言語に翻訳できるほど正確です。 実際のところ、入力内容にさまざまな言語が混在していても、システムがターゲット言語を検出して翻訳できるようになっています。 こういった場合、精度はそれほど高くないかもしれませんが本当に言いたいことがそれなりに理解できるようになります。
この統合モデルを訓練するために、当社はまず利用可能なオープンソースのデータ、当社独自のバーチャル空間内の翻訳データ、人の手で仕分け済みのチャット文の翻訳、一般的にチャットでよく使われる文章やフレーズを使って事前に訓練を行いました。 また、当社では翻訳のクオリティを測定するために独自の翻訳評価指標とモデルを構築しました。 既製の翻訳クオリティ評価指標のほとんどは、AIによる翻訳内容を特定の実際のデータまたは翻訳サンプルと比較し、主に内容の理解しやすさに焦点を当てています。 当社がしたかったのは、 実際の翻訳データを使用しないで翻訳のクオリティを評価することです。
当社では正確さ(加筆、脱字、誤訳の有無)、流暢さ(句読点、スペル、文法)、間違った参照(本文の他の部分との不一致)など、多方面から検証しています。 当社はこのようなエラーを深刻度に応じてレベル(致命的エラー、重大エラー、軽度のエラー)を仕分けしています。 当社はクオリティを評価するために機械学習モデルを構築し、人間が仕分けしたエラーの種類とスコアを使って訓練しました。 次に多言語モデルを微調整して単語レベルのエラーとその種類を予測し、多角的な基準を使ってスコアを計算しました。 これにより、エラーの質と種類を包括的に理解することができます。 このように原文と機械翻訳を使用することで実際的な翻訳データがなくても翻訳のクオリティを推定してエラーを検出できます。 このクオリティ測定の結果を使えば翻訳モデルのクオリティをさらに向上させることができます。
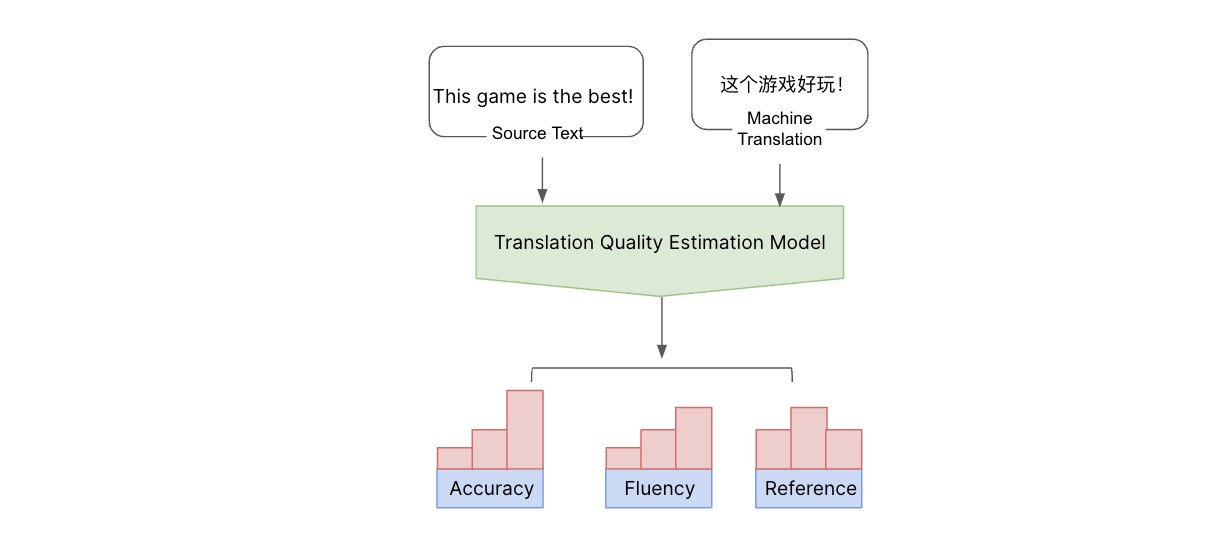
原文と機械翻訳の結果があれば、参照訳がなくても社内の翻訳クオリティ推定モデルを使用して機械翻訳のクオリティを推しはかることができます。 このモデルは、さまざまな側面から品質を推定し、エラーを致命的、重大、軽度に分類しています。
あまり一般的でない翻訳の組み合わせ(例えばフランス語からタイ語)の場合、クオリティの高いデータがあまりないため難しくなります。 この乖離に対処するため当社は逆翻訳を使いました。逆翻訳(バックトランスレーション)とは、コンテンツを元の言語に翻訳し直し、ソーステキストと比較して正確性を確認する方法です。 学習プロセスでは反復的な逆翻訳を使用し、この逆翻訳データと教師あり(仕分け済み)データを戦略的に組み合わせて使用することでモデルの学習対象となる翻訳データの量を増やしました。
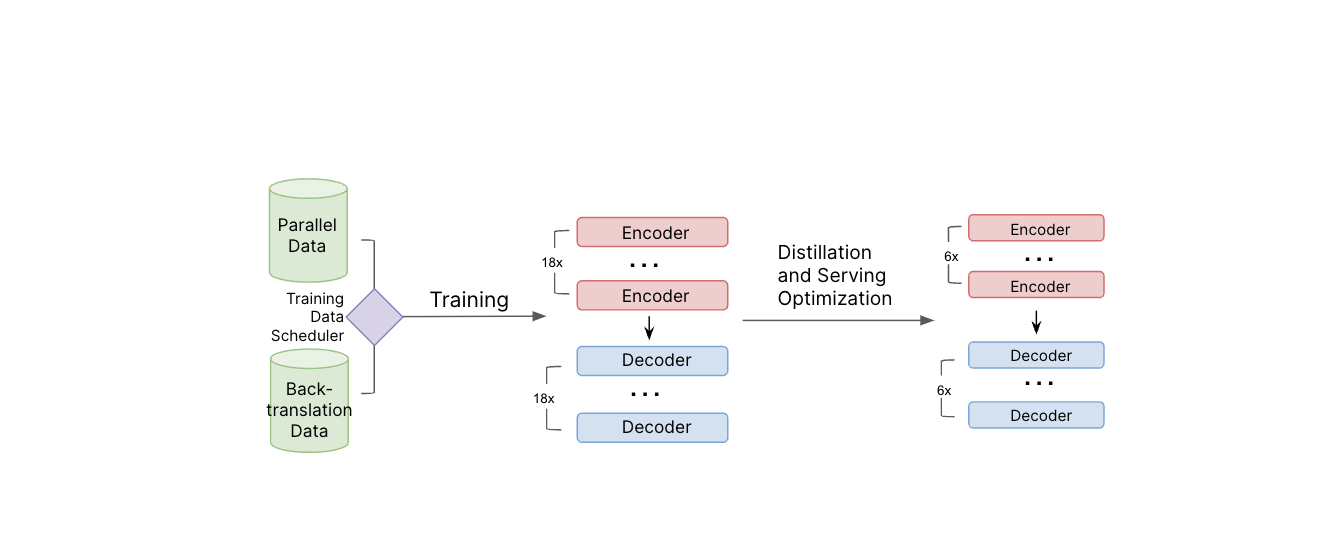
モデルの訓練パイプラインの図解。 モデルの学習には、並列データと逆翻訳データの両方が使用されます。 教師モデルの訓練が終わった後、当社は「蒸留」やその他のサービス最適化技術を使ってモデルサイズを縮小し、サービス効率を向上させます。
モデルが最近のスラングを理解できるようにするため、人間の評価担当者に各言語の流行語や若者言葉の翻訳を依頼した内容を学習データに入れました。 今後も定期的にこの作業を繰り返し、最新のスラングをシステムに反映させていく予定です。
出来上がったチャット翻訳モデルにはパラメータが約10億個あります。 このような大規模モデルで翻訳を実行して大規模なサービスを提供するには法外なリソースを消費しなければならず、リアルタイムの会話に対応するには時間がかかりすぎるため、毎秒5,000回以上のチャットに対応するためには遅延時間を低くすることが重要です。 そこで当社はこの大規模翻訳モデルにstudent-teacher(生徒と教師)型学習を使用し、より小型で軽量なモデルを構築しました。 当社は、蒸留、量子化、モデルコンパイル、その他のサービス最適化に貢献する方法を適用し、モデルのサイズを6億5,000万パラメータ以下に縮小し、サービス効率を向上させました。 さらに当社はバーチャル空間内で行われたテキストチャットのAPIを変更し、元のメッセージと翻訳されたメッセージの両方を相手の端末に送信するようにしました。 これによって受信者は母国語でメッセージを見たり、翻訳されていない送信者からのメッセージを原文に素早く切り替えたりすることができます。
最終的な言語モデルの準備ができたら、モデルサーバーと接続するバックエンドを実装しました。 このバックエンドでは、追加のチャット翻訳ロジックを使ってシステムを当社にある通常の信頼・安全部門で使用しているシステムと統合します。 これによって翻訳されたテキストに他のテキストと同じレベルの内容審査をしたり、当社のポリシーに違反する語句の検出やブロックができるようになります。 安全性と民度を高く保つことはRobloxのすべての活動で一番大切なものなのでパズルに例えると、これはとても重要な「ピース」でした。
継続的な精度の向上
テストでは、この新しい翻訳システムが当社のプラットフォーム上でのみなさんのエンゲージメントとセッションのクオリティを向上させていることがわかりました。 当社独自の指標によると、当社のモデルはRoblox上のコンテンツにある商業用の翻訳APIを凌駕しており、Roblox上でのみなさんのコミュニケーション方法の最適化に成功していることを示しています。 これを使えば違う言語圏の友達と連絡を取り合ったり、ゲームをしたり、買い物をしたり、共同作業をしたりできるようになるのでプラットフォーム上でのみなさんのユーザー体験が今後どのように改善されるかを楽しみにしています。
みなさんが自分の母国語を使って途切れなく自然な会話ができるようになれば、「楽しい気持ちと思いやりで10億人をつなぐ」という当社の目標に近づくことができます。
より良い訓練データをモデルに提供して翻訳の精度をさらに向上させるために、当社ではプラットフォームを使っているみなさんが翻訳についてフィードバックを提供し、システムがもっと速く翻訳のクオリティを改善できるようにするツールを展開していく予定です。 これを使えば、誤訳を見つけたときに誰かが教えてくれたり、モデルを改善するために、さらにいい訳文を学習データに追加したりできるようになります。
こういった翻訳は現在、当社が対応中の16ヶ国語すべてで利用可能になっています。 当社は、すべての対応言語のチャットでよく使われるフレーズや最新の俗語だけでなく、当社のバーチャル空間内から最新の翻訳例を使ってモデルをアップデートし続けます。 さらに、この構造によって新しい言語でも十分な学習データがあれば比較的少ない労力でモデルに学習させることができます。 さらに、当社では画像上のテキスト、テクスチャ、3Dモデルなど、あらゆるものを多角的に自動翻訳する方法を模索しています。
そして、当社は新しい分野である自動音声 チャットの翻訳などにも取り組んでいます。 フランス語を話す人が、ロシア語しか話せない人とRobloxで音声チャットができることをイメージしてみてください。 両者とも、声の高低やリズム、声色から伝わってくる気持ちまで、自国語でしかも低遅延で会話して理解しあうことができる状態です。 今は、これがSF漫画の世界のことのように思えるかもしれませんが、これを実現するには時間がかかっても当社はこれからも翻訳事業に邁進していくつもりです。 そう遠くない将来、Robloxは世界中のみなさんがテキストチャットだけでなく、ありとあらゆる手段で途切れなく簡単にコミュニケーションできる場所になるでしょう。